A Generic Feature Selection Method for Background Subtraction Using Global Foreground Models
Marc Braham and Marc Van Droogenbroeck
Abstract
Over the last few years, a wide variety of background subtraction algorithms have been proposed for the detection of moving objects in videos acquired with a static camera. While much effort have been devoted to the development of robust background models, the automatic spatial selection of useful features for representing the background has been neglected. In this paper,
we propose a generic and tractable feature selection method for background subtraction. Interesting contributions of this work are the proposal of a selection process coherent with the segmentation process and the exploitation of global foreground models in the selection strategy. Experiments conducted on the ViBe algorithm show that
our feature selection technique improves the segmentation results.
Keywords: background subtraction, feature selection, foreground modeling, change detection, ViBe
1 Introduction
Detecting moving objects in video sequences provides a valuable information for various applications such as video coding
[11], depth extraction from video
[14], or intelligent vision systems
[21]. A straightforward approach for motion detection is background subtraction, typically used in tracking systems, for its ability to detect moving objects without any assumption about their appearance, size or orientation
[34, 12]. The process consists in building a model of the static scene, which is named
background, and updating this model over time to account for luminance and structural changes in the scene. The background model is subtracted from the current frame, and pixels or regions with a noticeable difference are assumed to belong to moving objects (the
foreground). A background subtractor is thus a two-class classifier (foreground or background).
While conceptually simple, background subtraction still remains a difficult task because of the variety of challenging situations that occur in real world scenes. For instance, pixels may be erroneously classified as foreground in the presence of camera jitter, dynamic background (such as swaying trees or sea waves) or illumination changes. On the other hand, camouflage (i.e. foreground and background sharing similar colors) generate many false negative detections.
To deal with these challenging situations, a plethora of background subtraction techniques have been proposed (see
[13] or
[31] for a recent and comprehensive classification of these techniques including more than 300 references). They differ, among other things, in the features chosen to build the background model. According to
Bouwmans [31], five categories of features are frequently used: color features, edge features, texture features, motion features, and stereo features. Color features refer mainly to the color components of color spaces which can be processed separately or jointly. The RGB domain is the most popular
[1, 22], but some authors exploit other color spaces such as HSV
[25] or YCbCr
[6] in order to increase invariance with respect to brightness changes, and thus illumination changes and shadows. Gradient features
[27] and texture features such as LBP histogram
[19] or its variants
[4, 5] offer a robust solution to illumination changes but might be unsuitable in image areas with poor texture. Motion features, such as optical flow
[18], should be particularly interesting for scenes where the foreground is moving continuously (absence of temporarily stopped objects) and depth features acquired with range cameras such as the Kinect camera
[2] are (to some degree) insensitive to lighting conditions but cannot be computed when objects are far from the camera.
In conclusion, there seems to be no agreement on a unique feature performing better than any other feature independently of the background and foreground properties. Surprisingly, this is not considered in practice. Almost all existing background subtraction techniques operate with a uniform feature map in the sense that the features used to model the background and perform the detection are the same for all pixels of the image, thus ignoring the non-uniformity of the spatial distribution of background properties and neglecting the foreground properties. Recently,
Bouwmans concluded in a comprehensive survey paper
[31] that feature selection in background subtraction is still an open problem and may be one of the main future developments in this field.
In this paper, we propose a generic method for the spatial selection of the most significant features and we assess it for the ViBe technique. The main novelties of our work are: (1) a dedicated feature selection process that is coherent with the background subtraction process, and (2) the use of global foreground models in the selection strategy. The rest of the paper is organized as follows. Section
2↓ reviews the related work and presents the main limitations of existing selection methods. We provide the details of our method in Section
3↓. Experiments showing the benefits of our method are described in Section
4↓. Finally, Section
5↓ concludes the paper.
2 Related work
Li et al. [15] were among the first to express the need for modeling distinct part of the image with different features. They describe the background image as consisting of two pixel categories, static pixels and dynamic pixels, and incorporate this model in a Bayesian framework. Static pixels belong to stationary objects such as walls or room furniture whereas dynamic pixels refer to non stationary objects such as swaying trees or sea waves. Color and gradient statistics are used to describe static pixels while color co-occurrence statistics describe dynamic pixels. As the correspondence between a pixel category and the features used to describe it is fixed, the selection strategy reduces to an identification process of static and dynamic pixels. A temporal difference between two consecutive video frames is used for this purpose. Unfortunately, this method lacks of generality as the cardinality of the feature set, that is the number of candidate features or group of features, is limited to two (one group of features for static pixels and one other for dynamic pixels).
Parag et al. [33] introduced a more general feature selection framework requiring a set of training images free of foreground objects. The set of training images is divided into two parts. The first one generates a background statistical model for each feature of the feature set. These statistical models are used for the computation of background probability estimates (for each candidate feature) with the Kernel Density Estimation (KDE)
[1] on the remaining part of the training set and on synthetic foreground examples. The computed estimates feed the training of a RealBoost classifier
[26]. The resulting classifier selects the most useful features for each pixel and assigns a confidence weight to each of them. While this framework can be used with an arbitrary number of candidate features, it has a serious drawback. Indeed, the synthetic foreground examples used for boosting are generated randomly from a uniform distribution. In other words, all candidate features are assumed to be uniformly distributed for foreground objects. This assumption is not valid because of the wide variety of foreground statistical distributions among different features. For instance, gradient has a foreground probability density function (FG-pdf) concentrated around low values while RGB color components have a wider FG-pdf. This may explain why the classification performance of
Parag’s framework
[33] decreases when gradient features are added to the feature set. In our work, we overcome this major limitation by means of global statistical foreground models.
Another boosting-based approach for feature selection was proposed by
Grabner et al. [9, 10]. The main novelty of their work is the spatio-temporal nature of the selection through on-line boosting. However, since the method is based on self-learning (
i.e. classifier predictions feed model updates), the background model can end up in catastrophic state, as mentioned in
[8]. Once again, unrealistic assumptions about the statistical distributions of foreground features are used (a uniform distribution is assumed for the gray value of foreground objects and serves as a basis for computing other feature distributions).
Recently,
Javed et al. [28] included a dynamic feature selection strategy for background subtraction in an
Online Robust Principal Component Analysis (OR-PCA) framework. Feature statistics, in terms of means and variances, are used as a selection criterion. Unlike aforementioned purely spatial or spatio-temporal selection approaches, their method is exclusively temporal-based, which means that all pixels use the same features for the foreground segmentation. The non-uniformity of the spatial distribution of background properties is thus ignored.
3 Proposed selection strategy
A schematic view of our feature selection strategy is given in Fig.
1↓. Like in
Parag’s work
[33], our selection process occurs during a training phase, which allows to avoid extra computations during normal background subtraction operations. This training phase is divided into three parts, represented by boxes [1], [2], and [3] in Fig.
1↓. The first part consists to accumulate images free of foreground objects, typically a few hundreds at a framerate of 30 frames per second, which are further processed to build local background statistical models. The second training part requires another sequence of images, this time including foreground objects. These images are not saved into memory, but processed by a background subtraction algorithm in order to build a global foreground statistical model for each candidate feature of the feature set. The third part of the training phase selects the best feature/threshold combination; this process is
local, meaning that it is performed for each pixel individually. The goal of the selection process consists to detect which feature is most appropriate to discriminate between the local background and the foreground at the frame level. To guarantee some consistency with the segmentation process, the selection step is fed by supplementary information relating to the background model of the segmentation algorithm, and to the application performance metric (see box [4] in Fig.
1↓). All these steps are detailed in the following subsections.
3.1 Estimation of the foreground: local vs global foreground models
Background subtraction is a classification problem between the background or foreground classes. It is well known that the classification performance of a classifier is dependent on the discriminating power of the used features. Therefore, an optimal classifier should select the best feature locally, that is for each pixel separately, to maximize its capability to distinguish between the local background values and the local foreground values, which indirectly implies that we are able to estimate the corresponding statistical distributions for any feature.
Obtaining reliable local background statistical models is realistic and common. Indeed, local background feature values are relatively stable (or at least predictable). Moreover, the pixel-wise probability to observe a background sample (we name this as the local BG-prior) is much higher than the local FG-prior. Subsequently, it suffices to collect a small set of background training images to estimate the local BG feature distributions. However, estimating local foreground distributions is more complex. The two main difficulties are that (1) most features have a wide FG-pdf, and (2) local FG-priors are often low with respect to BG-priors, which means that foreground might not be encountered locally during the training phase. In fact, estimating the local foreground distributions reliably would require an extremely long observation period, which is clearly intractable. There is thus an imbalance between the estimation of local background or foreground characteristics.
To overcome this estimation problem, we assume that the local foreground distribution of a feature can be approximated by its global foreground distribution. There is an important advantage to assume this. Indeed, it might be that a moving object is very different from the background for some areas of the image, but close for other areas. A global estimation will help to learn from the foreground values detected in the easiest areas of the scene. Mathematically, assuming that the distributions are represented by histograms of observed values, and denoting by LHf the matrix of local histograms for a feature f, the global histogram GHf of feature f is given by:
where
b is a particular bin and
(x, y) refers to the coordinates in the image. For a multi-dimensional feature (for instance the RGB feature which is a tri-dimensional feature, to the contrary of the individual color components: R,G, or B), equation
(1↑) becomes:
where
D is the number of dimensions of the feature. Note that our assumption of a uniform spatial distribution of foreground feature values is not perfectly true, especially because of the modification of geometrical and colorimetric properties of foreground objects in the image as they move across the scene. Despite that, we believe that the approach is appropriate. The main benefit results from the considerable reduction of the observation time required for estimating the local foreground distributions. A practical estimation becomes thus feasible.
In summary, the second training stage (named “Global FG models estimation” in Fig.
1↑) is performed as follows. We feed a background subtraction algorithm (named “estimator” in the remainder of the paper) with a sequence of training images including foreground objects. The choice of the estimator is not critical; state-of-the-art techniques, such as SuBSENSE
[30] or PAWCS
[29], are good candidates to segment foreground objects. Note that a fast estimator is not necessary because there is no real-time requirement during the training phase. The segmentation masks of the estimator are processed to build the
#f global foreground models,
#f denoting the cardinality of the feature set.
3.2 Coherence between selection, segmentation, and application
While some authors have expressed the need for modeling distinct part of the image with different features for background subtraction
[15, 33, 9], none of them noticed that the best feature map may depend on elements unrelated to background or foreground statistical properties. We innovate in this paper by considering the type of background model used by the segmentation algorithm (see box [5] in Fig.
1↑). Some features may be adapted to specific background models, while performing badly for others. This statement was confirmed recently by
López-Rubio et al. [7]. They showed that, while
Haar-like features
[23] were reported to be adapted to KDE background models in the context of feature combination
[3], they have an insufficient discriminating power in a probabilistic mixture-based approach. A generic algorithm should therefore select, locally, the most discriminating feature
for each background model individually.
Another important element of our framework is the inclusion of coherence with respect to the application. Some applications require to minimize the false alarm rate while maintaining a desired recall, whereas others need to maximize the recall while maintaining a relatively low false alarm rate. As each feature choice tends to favor particular metrics, the performance metric of the application should be considered during the selection process. Therefore, we use the application performance metric to evaluate the capability of a feature to discriminate between local background samples and global foreground samples. Note however that the framework is incompatible with prior-dependent performance metrics, such as the popular
F1 measure. The origin of this limitation is the modification of the local FG-prior due to the construction of the global foreground histograms. Indeed, the number of global foreground samples collected during the second step of the learning phase (see box [2] in Fig.
1↑) is much higher than the number of local background samples of a pixel (in fact equal to the number of background training images). Therefore, as the selection process introduces a large bias in the estimation of the local FG-prior, it is strongly recommended to use prior-independent metrics, such as the geometrical mean
[24] or the Euclidean distance in ROC space introduced in
[16].
3.3 Local feature/threshold selection process
Our generic feature selection method for background subtraction is presented in Algorithm
1↓. This algorithm is implemented in the [3] box of Fig.
1↑. Note that the background subtraction step involves the choice of matching thresholds (one threshold per feature) for comparing current input feature values with local background feature values. For instance, in the case of ViBe
[22], the radius of the color sphere is the matching threshold used to compare RGB feature values. These thresholds affect the results of the corresponding features. For this reason, we feed the generic selection algorithm with
#f sets of
#t candidate thresholds (one set of candidate thresholds per feature), where
#t denotes the cardinality of the threshold sets (assumed equal for each threshold set, for convenience) and let the algorithm select the best feature/threshold combination, locally.
The selection process consists in a simulation of the target background model for each feature. Firstly, the simulated local feature background models are build. In the case of ViBe’s background model
[22], this is performed by selecting, randomly and for each feature, 20 values among the
K background feature values available at coordinates
(x, y),
K denoting the number of background training images. Then, each model is assessed for its capability to predict the correct class of input samples, these one being both (1) all local samples of the background training images, and (2) all global samples collected in the corresponding global FG histogram. As the predictions depend on the matching threshold, this capability is assessed for all candidate thresholds of a given feature, and described by a confusion matrix
[32]. The performance metric is computed from the confusion matrix and the best feature/threshold combination is selected.
Algorithm 1 Generic algorithm for local feature/threshold selection.
4 Experiments
4.1 Description of the methodology
We particularized our generic method for the ViBe background subtraction algorithm
[22], and evaluated it for the CDNet 2012 dataset
[20]. The feature set contains 9 individual color components (
#f = 9), taken from the 3 common color spaces RGB, HSV, and YCbCr:
Each feature is quantized into 256 bins. For this purpose, the saturation S and the value V (resp. the hue H) are rescaled linearly from the range
[0, 1] (resp.
[0, 360)) to the range
[0, 255]. The pre-defined set of possible thresholds is
The Euclidean distance in the ROC space, introduced in
[16] and defined as
where
FNR and
FPR denote respectively the false negative rate and the false positive rate, is our prior-independent performance metric. Its behavior is close to that of the geometrical mean of
Barandela et al. [24], but it is easier to interpret because it measures the distance between a classifier and the theoretically best classifier, also called
oracle (top left corner of the ROC space). We want to minimize this distance, because lower distances mean being closer to the oracle.
For the purposes of our analysis, we have selected three categories of videos of CDNet
[20]: “
Baseline”, “
Camera jitter”, and “
Dynamic background”. Other categories are less relevant, because either they are inappropriate (“
Thermal” only contains grayscale images), or because our algorithm is not designed to deal with the particularities of that category (“
Shadow” for example). In fact, it is designed to be robust against camouflage and against background changes that occur during the first part of the training phase (see box [1] in Fig.
1↑), such as camera jitter, dynamic backgrounds, or illumination changes. Intermittent object motion and shadows are related to foreground objects, and thus cannot be learned during the background learning step.
CDNet
[20] provides videos split for the needs of two phases: (1) an initialization phase (ground-truth images are not provided) and (2) an evaluation phase (ground-truth images are provided). Images of the initialization phase are used to train the background model. For videos containing moving objects during this phase, we have manually selected background images, when it was possible. Otherwise, we have manually defined bounding boxes around moving objects and their shadows, to help discarding these areas for building the background models. The first half of images of the evaluation phase is used to estimate the global foreground models, using PAWCS
[29] as an estimator. After this step, we perform the local feature/threshold selection. The computed feature and threshold maps are provided to ViBe (designated by ViBe-FT), which then detects the foreground for the second half of images of the evaluation phase. We evaluate the segmentation masks of ViBe-FT on this second half.
4.2 Results and discussion
The results of ViBe-FT are compared to those of the original ViBe
[22] algorithm when applied on the 9 color components separately,
i.e. with uniform feature and threshold maps, denoted by {ViBe-R, ViBe-G
, …, ViBe-Cb, ViBe-Cr}. The uniform thresholds have been set to {11,11,11,11,11,11,11,3,3} (these values were found to be well suited to the corresponding features). Moreover, we report the results of ViBe when only the feature selection process of Algorithm
1↑ is activated (thresholds are fixed to the aforementioned values), designated by ViBe-F.
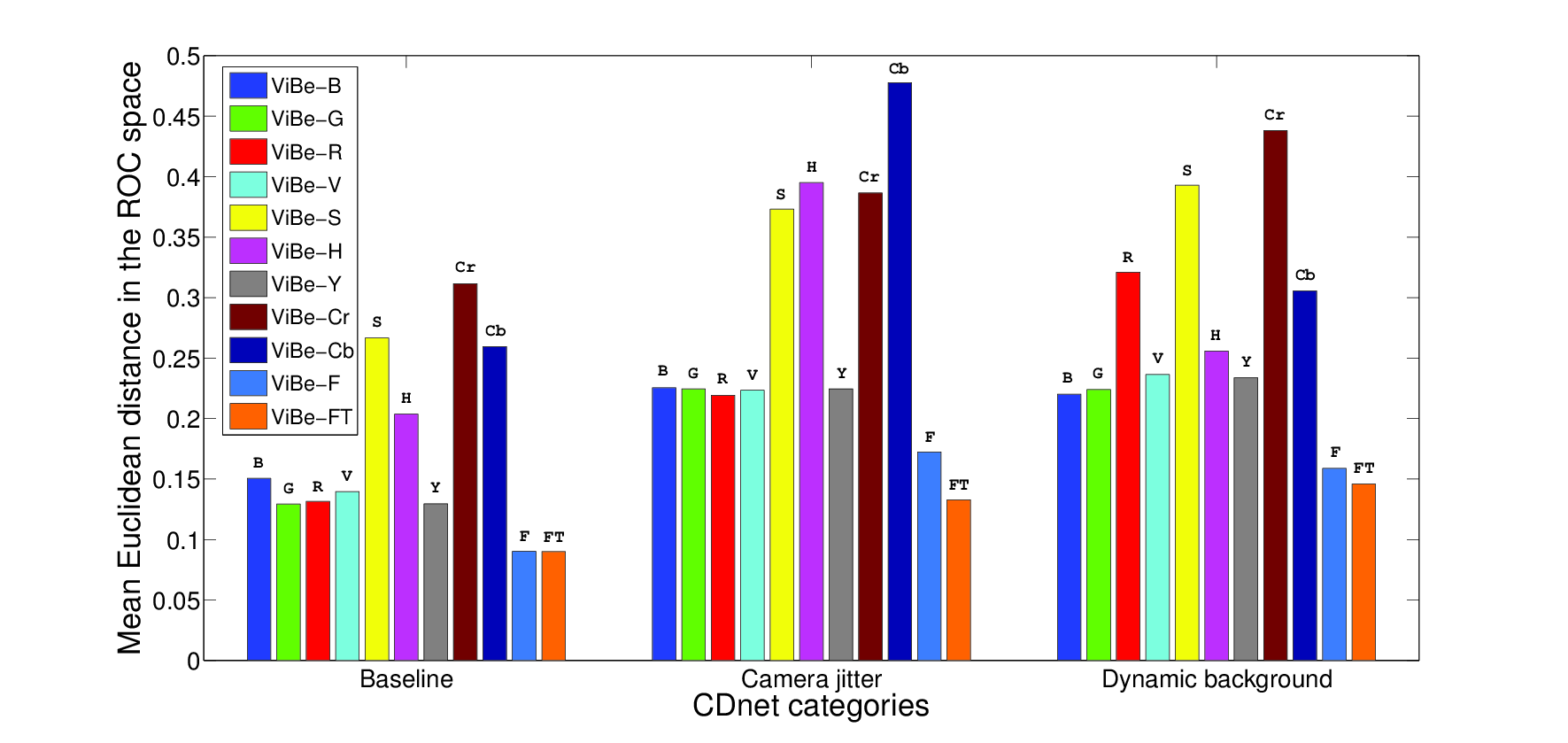
Results displayed in Fig.
2↓ show that the proposed local feature selection framework significantly improves the detection results. For each category, our feature and threshold maps reduce the mean Euclidean distance of ViBe. This means that our framework pushes the background subtraction algorithm towards the oracle of the ROC space, and thus improves the detection. The conclusion is similar when the threshold selection mechanism is deactivated (denoted by “ViBe-F” on the graphic), which proves the robustness of the local feature selection process with respect to the threshold values.
Fig.
3↓ shows several feature maps obtained after the local feature selection process, as well as the resulting improved segmentation masks. Note that these improvements are significant despite that (1) a small set of candidate features was used, and (2) the number of training frames used to estimate the global foreground distributions is relatively small (744 on average), which confirms the importance of a
global estimation for obtaining reliable foreground distributions. The computational complexity of the selection process is
O(#f#t). Note however that, as this process occurs during an off-line training phase, it does not affect the computational complexity of the detection task.
5 Conclusions
In this paper, we present a generic feature selection method for background subtraction. Unlike previous approaches, we estimate the foreground feature statistical distributions at the frame level. Features are selected locally depending on their capability to discriminate between local background samples and global foreground samples for a specific background model and for a chosen performance metric. Experiments led for the ViBe algorithm show that our method significantly improves the performance in the ROC space.
Acknowledgments
Marc
Braham has a grant funded by the FRIA (
http://www.frs-fnrs.be). We are also grateful to Jean-François
Foulon for his help.
References
[1] A. Elgammal, D. Harwood, L. Davis. Non-Parametric Model for Background Subtraction. European Conference on Computer Vision (ECCV), 1843:751-767, 2000. URL http://dx.doi.org/10.1007/3-540-45053-X_48.
[2] B. Freedman, A. Shpunt, M. Machline, Y. Arieli. Depth Mapping Using Projected Patterns, US Patent 8150142. 2012.
[3] B. Han, L S. Davis. Density-Based Multifeature Background Subtraction with Support Vector Machine. IEEE Transactions on Pattern Analysis and Machine Intelligence, 34(5):1017-1023, 2012. URL http://dx.doi.org/10.1109/TPAMI.2011.243.
[4] G.-A. Bilodeau, J.-P. Jodoin, N. Saunier. Change Detection in Feature Space Using Local Binary Similarity Patterns. International Conference on Computer and Robot Vision (CRV):106-112, 2013. URL http://dx.doi.org/10.1109/CRV.2013.29.
[5] C. Silva, T. Bouwmans, C. Frélicot. An EXtended Center-Symmetric Local Binary Pattern for Background Modeling and Subtraction in Videos. International Conference on Computer Vision Theory and Applications (VISAPP):395-402, 2015.
[6] F. Kristensen, P. Nilsson, V. Öwall. Background Segmentation Beyond RGB. Asian Conference on Computer Vision (ACCV), 3852:602-612, 2006. URL http://dx.doi.org/10.1007/11612704_60.
[7] F. López-Rubio, E. López-Rubio. Features for Stochastic Approximation Based Foreground Detection. Computer Vision and Image Understanding, 133:30-50, 2015. URL http://dx.doi.org/10.1016/j.cviu.2014.12.007.
[8] H. Grabner, C. Leistner, H. Bischof. Time Dependent On-line Boosting for Robust Background Modeling. International Conference on Computer Vision Theory and Applications (VISAPP):612-618, 2007.
[9] H. Grabner, H. Bischof. On-line Boosting and Vision. IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), 1:260-267, 2006. URL http://dx.doi.org/10.1109/CVPR.2006.215.
[10] H. Grabner, P. Roth, M. Grabner, H. Bischof. Autonomous Learning of a Robust Background Model for Change Detection. IEEE International Workshop on Performance Evaluation of Tracking and Surveillance (PETS):39-46, 2006.
[11] J. Xiao, L. Liao, J. Hu, Y. Chen, R. Hu. Exploiting Global Redundancy in Big Surveillance Video Data for Efficient Coding. Cluster Computing, 18(2):531-540, 2015. URL http://dx.doi.org/10.1007/s10586-015-0434-z.
[12] J.-P. Jodoin, G.-A. Bilodeau, Nicolas Saunier. Urban Tracker: Multiple Object Tracking in Urban Mixed Traffic. IEEE Winter Conference on Applications of Computer Vision (WACV):885-892, 2014. URL http://dx.doi.org/10.1109/WACV.2014.6836010.
[13] P.-M. Jodoin, S. Piérard, Y. Wang, M. Van Droogenbroeck. Overview and Benchmarking of Motion Detection Methods. In Background Modeling and Foreground Detection for Video Surveillance (T. Bouwmans and F. Porikli and B. Hoferlin and A. Vacavant, ed.). Chapman and Hall/CRC, 2014. URL http://dx.doi.org/10.1201/b17223-30.
[14] Kevin Karsch, Ce Liu, Sing Bing Kang. DepthTransfer: Depth Extraction from Video Using Non-Parametric Sampling. IEEE Transactions on Pattern Analysis and Machine Intelligence, 36(11):2144-2158, 2014. URL http://dx.doi.org/10.1109/TPAMI.2014.2316835.
[15] L. Li, W. Huang, Y.-H. Gu, Q. Tian. Statistical Modeling of Complex Backgrounds for Foreground Object Detection. IEEE Transactions on Image Processing, 13(11):1459-1472, 2004. URL http://dx.doi.org/10.1109/TIP.2004.836169.
[16] M. Braham, A. Lejeune, M. Van Droogenbroeck. A Physically Motivated Pixel-Based Model for Background Subtraction in 3D Images. International Conference on 3D Imaging (IC3D):1-8, 2014. URL http://dx.doi.org/10.1109/IC3D.2014.7032591.
[17] M. Braham, M. Van Droogenbroeck. A generic feature selection method for background subtraction using global foreground models. Advanced Concepts for Intelligent Vision Systems (ACIVS), 2015. URL http://hdl.handle.net/2268/185047.
[18] M. Chen, Q. Yang, Q. Li, G. Wang, M.-H. Yang. Spatiotemporal Background Subtraction Using Minimum Spanning Tree and Optical Flow. European Conference on Computer Vision (ECCV), 8695:521-534, 2014. URL http://dx.doi.org/10.1007/978-3-319-10584-0_34.
[19] M. Heikkilä, M. Pietikäinen. A Texture-Based Method for Modeling the Background and Detecting Moving Objects. IEEE Transactions on Pattern Analysis and Machine Intelligence, 28(4):657-662, 2006. URL http://dx.doi.org/10.1109/TPAMI.2006.68.
[20] N. Goyette, P.-M. Jodoin, F. Porikli, J. Konrad, P. Ishwar. changedetection.net: A New Change Detection Benchmark Dataset. IEEE International Conference on Computer Vision and Pattern Recognition Workshops (CVPRW):1-8, 2012. URL http://dx.doi.org/10.1109/CVPRW.2012.6238919.
[21] Nuria M. Oliver, Barbara Rosario, Alex P. Pentland. A Bayesian Computer Vision System for Modeling Human Interactions. IEEE Transactions on Pattern Analysis and Machine Intelligence, 22(8):831-843, 2000. URL http://dx.doi.org/10.1109/34.868684.
[22] O. Barnich, M. Van Droogenbroeck. ViBe: A Universal Background Subtraction Algorithm for Video Sequences. IEEE Transactions on Image Processing, 20(6):1709-1724, 2011. URL http://dx.doi.org/10.1109/TIP.2010.2101613.
[23] P. Viola, M. Jones. Rapid Object Detection Using a Boosted Cascade of Simple Features. IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), 1:511-518, 2001. URL http://dx.doi.org/10.1109/CVPR.2001.990517.
[24] R. Barandela, J. Sánchez, V. García, E. Rangel. Strategies for Learning in Class Imbalance Problems. Pattern Recognition, 36(3):849-851, 2003. URL http://dx.doi.org/10.1016/S0031-3203(02)00257-1.
[25] R. Cucchiara, C. Grana, M. Piccardi, A. Prati. Detecting Moving Objects, Ghosts, and Shadows in Video Streams. IEEE Transactions on Pattern Analysis and Machine Intelligence, 25(10):1337-1342, 2003. URL http://dx.doi.org/10.1109/TPAMI.2003.1233909.
[26] Robert E. Schapire, Yoram Singer. Improved Boosting Algorithms Using Confidence-rated Predictions. Machine Learning, 37(3):297-336, 1999. URL http://dx.doi.org/10.1023/A:1007614523901.
[27] S. Gruenwedel, P. Van Hese, W. Philips. An Edge-Based Approach for Robust Foreground Detection. Advanced Concepts for Intelligent Vision Systems (ACIVS), 6915:554-565, 2011. URL http://dx.doi.org/10.1007/978-3-642-23687-7_50.
[28] S. Javed, A. Sobral, T. Bouwmans, S. Jung. OR-PCA with Dynamic Feature Selection for Robust Background Subtraction. ACM Symposium on Applied Computing:86-91, 2015. URL http://dx.doi.org/10.1145/2695664.2695863.
[29] P.-L. St-Charles, G.-A. Bilodeau, R. Bergevin. A Self-Adjusting Approach to Change Detection Based on Background Word Consensus. IEEE Winter Conference on Applications of Computer Vision (WACV):990-997, 2015. URL http://dx.doi.org/10.1109/WACV.2015.137.
[30] P.-L. St-Charles, G.-A. Bilodeau, R. Bergevin. SuBSENSE: A Universal Change Detection Method with Local Adaptive Sensitivity. IEEE Transactions on Image Processing, 24(1):359-373, 2015. URL http://dx.doi.org/10.1109/TIP.2014.2378053.
[31] T. Bouwmans. Traditional and Recent Approaches in Background Modeling for Foreground Detection: An Overview. Computer Science Review, 11:31-66, 2014. URL http://dx.doi.org/10.1016/j.cosrev.2014.04.001.
[32] T. Fawcett. An Introduction to ROC Analysis. Pattern Recognition Letters, 27(8):861-874, 2006. URL http://dx.doi.org/10.1016/j.patrec.2005.10.010.
[33] T. Parag, A. Elgammal, A. Mittal. A Framework for Feature Selection for Background Subtraction. IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), 2:1916-1923, 2006. URL http://dx.doi.org/10.1109/CVPR.2006.24.
[34] Z. Kim. Real Time Object Tracking Based on Dynamic Feature Grouping with Background Subtraction. IEEE International Conference on Computer Vision and Pattern Recognition (CVPR):1-8, 2008. URL http://dx.doi.org/10.1109/CVPR.2008.4587551.