Semantic background subtraction
M. Braham, S. Piérard and M. Van Droogenbroeck
September 2017
Original scientific paper available in
PDF
How to cite this work:
M. Braham, S. Piérard and M. Van Droogenbroeck, Semantic background subtraction,
IEEE International Conference on Image Processing (ICIP), Beijing, September 2017.
Summary
We introduce the notion of
semantic background subtraction, a novel framework for motion detection in video sequences. The key innovation consists to leverage object-level semantics to address the variety of challenging scenarios for background subtraction. Our framework combines the information of a semantic segmentation algorithm, expressed by a probability for each pixel, with the output of any background subtraction algorithm to reduce false positive detections produced by illumination changes, dynamic backgrounds, strong shadows, and ghosts. In addition, it maintains a fully semantic background model to improve the detection of camouflaged foreground objects. Experiments led on the CDNet dataset show that we managed to improve, significantly, almost all background subtraction algorithms of the CDNet leaderboard, and reduce the mean overall error rate of all the 34 algorithms (resp. of the best 5 algorithms) by roughly 50% (resp. 20%).
Keywords: background subtraction, change detection, semantic segmentation, scene labeling, classification
1 Introduction
Background subtraction is a popular approach for detecting moving objects in video sequences. The basic idea consists in comparing each video frame with an adaptive background model (which can be reduced to a single image) free of moving objects. Pixels with a noticeable difference are assumed to belong to moving objects (they constitute the foreground) while others are classified as background.
Over the last two decades, a large number of methods have been proposed for this task (see
[13, 19] for reviews). Most of them model the background and classify pixels using low-level features such as color components
[3, 12], edges
[20], texture descriptors
[16], optical flow
[11], or depth
[10]. A comprehensive review and classification of features used for background modeling can be found in
[18]. While most of these features can be computed with a very low computational load, they cannot address simultaneously the numerous challenges arising in real-world video sequences such as illumination changes, camouflage, camera jitter, dynamic backgrounds, shadows, etc. Upper bounds on the performance of pixel-based methods based exclusively on RGB color components were simulated in
[15]. In particular, it was shown that background subtraction algorithms fail to provide a perfect segmentation in the presence of noise and shadows, even when a perfect background image is available.
Our solution consists in the introduction of semantics. Humans can easily delineate relevant moving objects with a high precision because they incorporate knowledge from the semantic level: they know what a car is, recognize shadows, distinguish between object motion and camera motion, etc. The purpose of
semantic segmentation (also known as
scene labeling or
scene parsing) is to provide such information by labeling each pixel of an image with the class of its enclosing object or region. The task is difficult and requires the simultaneous detection, localization, and segmentation of semantic objects and regions. However, the advent of deep neural networks within the computer vision community and the access to large labeled training datasets have dramatically improved the performance of semantic segmentation algorithms
[8, 17, 5, 7]. These improvements have motivated their use for specific computer vision tasks, such as optical flow estimation
[9]. In this paper, we leverage object-level semantics for motion detection in video sequences and present a generic framework
to improve background subtraction algorithms with semantics
.
The outline of the paper is as follows. We describe the details of our semantic background subtraction framework in Section
2↓. In Section
3↓, we apply our proposed approach
to all the 34 background subtraction methods whose segmentation maps are available on the website of the
CDNet dataset
[21] (named CDNet hereafter) and discuss the results. Finally, Section
4↓ concludes the paper.
2 Semantic background subtraction
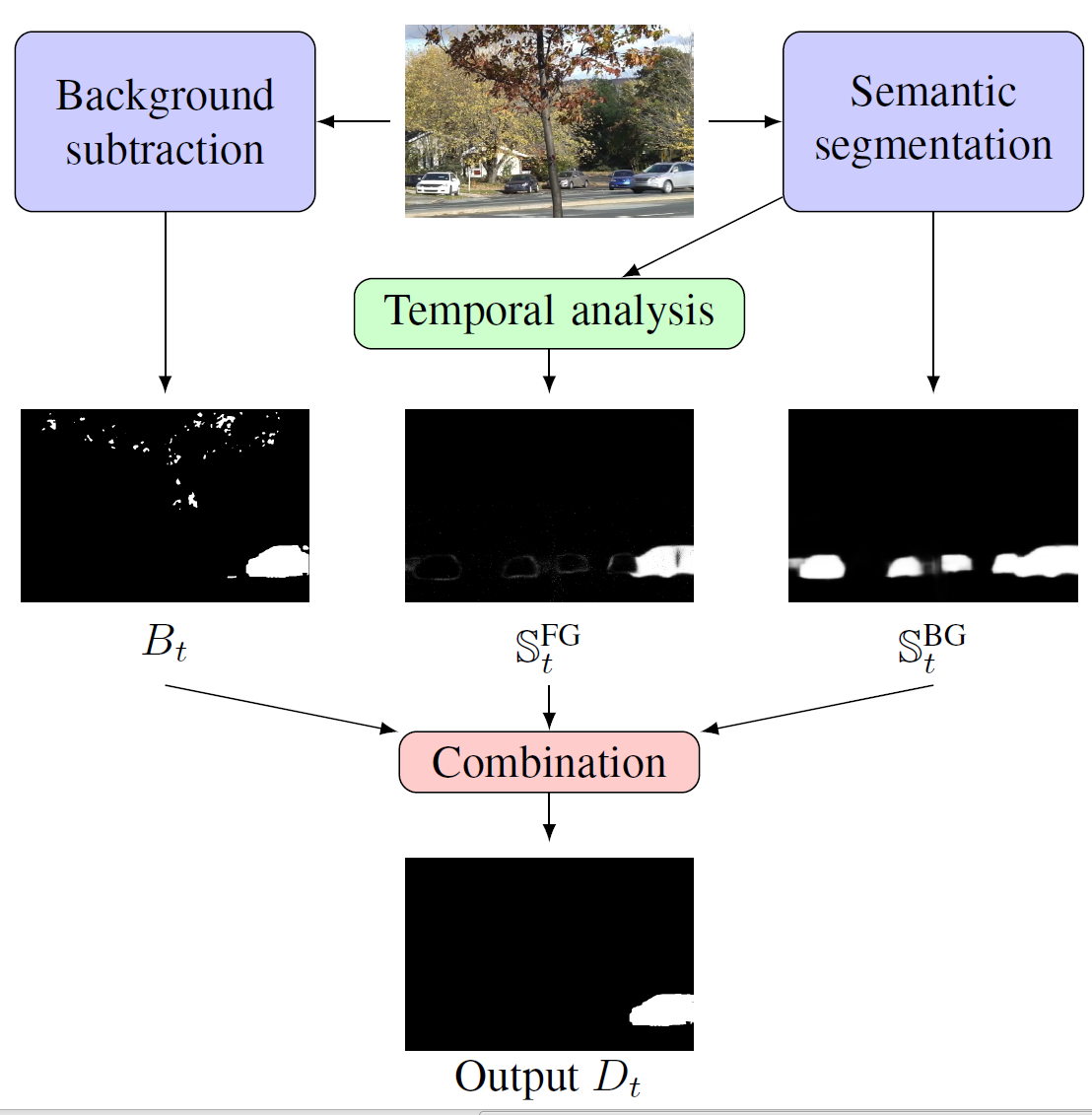
Our framework compensates for the errors of any background subtraction (named BGS hereafter) algorithm by combining, at the pixel level, its result
B ∈ {BG, FG} with two signals (
𝕊BG and
𝕊FG) derived from the semantics, as shown in Figure
1↑. While the first signal supplies the information necessary to detect many
BG pixels with high confidence, the second helps to detect
FG pixels reliably. The result of the combination is denoted by
D ∈ {BG, FG}. Our objective is to show the possibility of leveraging state of the art semantic segmentation algorithms to improve the performance of most BGS algorithms, without modifying them or accessing their internal elements (
e.g. their model and parameters).
2.1 Leveraging semantics to detect background pixels
Let C = {c1, c2, ..., cN} be a set of N disjoint object classes. We assume that the semantic segmentation algorithm outputs a real-valued vector vt(x) = [v1t(x), v2t(x), ..., vNt(x)], where vit(x) denotes a score for class ci at the pixel location x at time t. The probabilities pt(x ∈ ci) are estimated by applying a softmax function to vt(x). Let R (R ⊂ C) be the subset of all object classes semantically relevant for motion detection problems. The semantic probability is defined and computed as pS, t(x) = pt(x ∈ R) = ∑ci ∈ Rpt(x ∈ ci).
It is possible to leverage semantics to detect background, as all pixels with a low semantic probability value
pS, t(x) should be labeled as background, regardless of the decision
Bt(x). Therefore, we compare the signal
𝕊BGt(x) = pS, t(x) to a decision threshold
τBG, as given by rule 1:
Rule 1 provides a simple way to address the challenges of illumination changes, dynamic backgrounds, ghosts, and strong shadows, which severely affect the performances of BGS algorithms by producing many false positive detections. The optimal value of
τBG is related to the performance of the BGS algorithm for the
BG class, as explained in Section
3↓.
2.2 Leveraging semantics to detect foreground pixels
In order to help detecting the foreground, we have to use pS, t(x) in a different way than for rule 1, as semantically relevant objects may be present in the background (e.g. a car parked since the first frame of the video). To account for this possibility, our solution consists to maintain a purely semantic background model for each pixel. More precisely, we denote by Mt(x) the probability modeling the semantics of the background at the pixel x at time t. Typical initialization and updating steps of this semantic model can be the following:
with
→ α denoting a probability
α of application (
α is arbitrarily set to
0.00024 in our experiments). This conservative updating strategy was introduced in
[12] to avoid model corruptions due to intermittent and slow moving objects. The semantic background model allows to detect large increases of
pS, t(x), observed when a foreground object appears in front of a semantically irrelevant background (
e.g. a car moving on a road or a pedestrian walking in front of a building). This leads us to the following decision rule:
with the signal
𝕊FGt(x) = pS, t(x) − Mt(x), and
τFG denoting a second threshold, whose optimal value is related to the performance of the BGS algorithm for the
FG class, as explained in Section
3↓. Rule 2 aims at reducing the number of false negative detections due to camouflage,
i.e. when background and foreground share similar colors.
2.3 The BGS is used when semantics is not decisive
The semantic probability
pS, t(x) alone does not suffice for motion detection. This is illustrated by the case in which a semantically relevant object (
e.g. a car in the foreground) moves in front of a stationary object of the same semantic class (
e.g. a car parked in the background). The semantic probability
pS, t(x) being the same for both objects, it is impossible to distinguish between both. If conditions of rules 1 and 2 are not met, which means that semantics alone does not provide enough information to take a decision, we delegate the final decision to the BGS algorithm:
Dt(x) = Bt(x). The complete classification process is summarized in Table
1↓.
Table 1 Our combination of three signals for semantic BGS. Rows corresponding to “don’t-care” values (X) cannot be encountered, assuming that τBG < τFG.
The importance of both rules should be emphasized. Rule 1 always leads to the prediction of BG, so its use can only decrease the True Positive Rate TPR and the False Positive Rate FPR, in comparison to the BGS algorithm used alone. To the contrary, rule 2 always leads to the prediction of FG, and therefore its use can only increase the TPR and the FPR. The objective of improving both the TPR and the FPR can thus only be reached by the joint use of both rules.
3 Experimental results
We applied our framework to all the 34 BGS methods whose segmentation maps (which directly provide the binary decisions
Bt(x)) are available on the website of the CDNet dataset
[21] for 53 video sequences organized in 11 categories. We rely on a recent deep architecture, PSPNet
[5] (ranked
1st in the PASCAL VOC 2012 object segmentation leaderboard
[1] on the 6th of February 2017), trained on the ADE20K dataset
[2] to extract semantics, using a publicly available model
[6]. The last layer of the model provides a real value in each pixel for each of
150 object classes of the ADE20K dataset (
C). Our subset of semantically relevant objects is
R = {person, car, cushion, box, book, boat, bus, truck, bottle, van, bag, bicycle}, corresponding to the semantics of CDNet foreground objects.
In order to show the effectiveness of our framework, we compare the performances of BGS methods applied with or without semantics. The improvement is defined as
where
ER denotes the mean
Error Rate over a particular set of BGS methods and a set of categories from the CDNet dataset. We considered three policies to set
τBG and
τFG.
(1) Optimization based policy. First, we performed a grid search optimization, for each BGS algorithm specifically, to select the thresholds producing the best overall
F score:
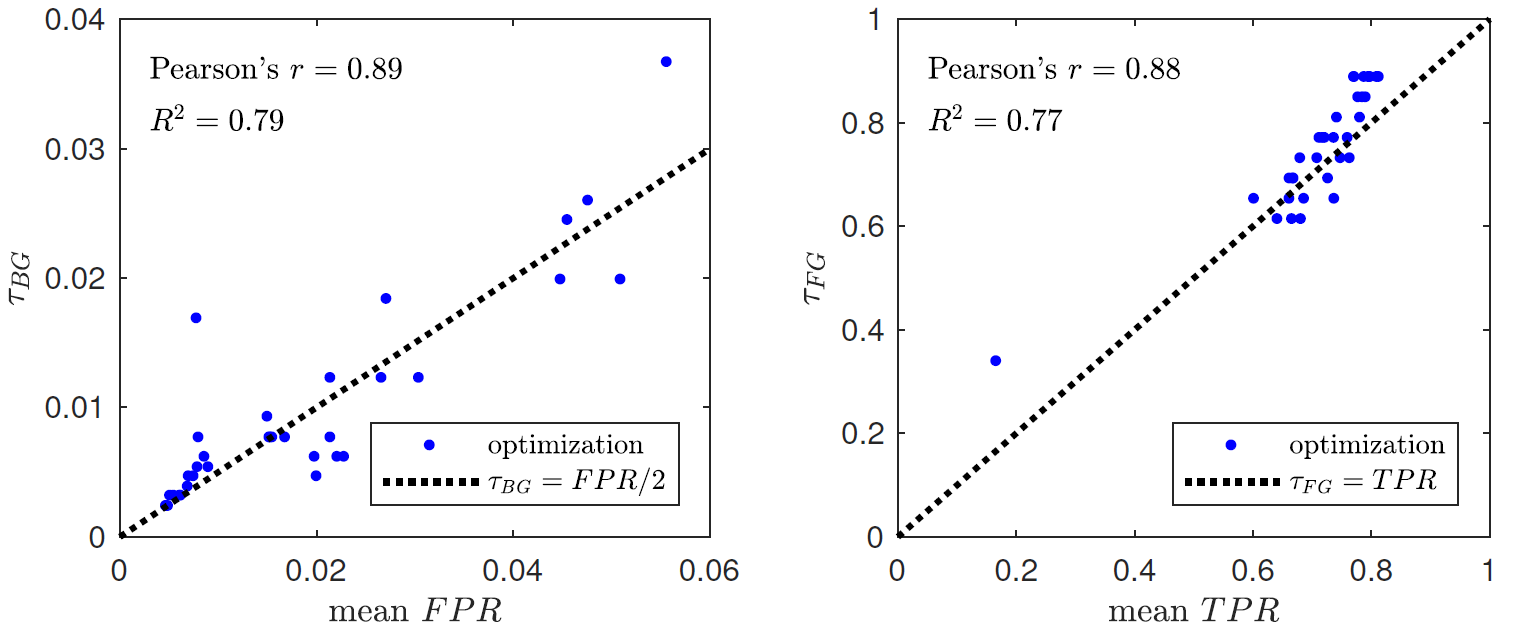
(2) Heuristics based policy. An analysis of these optimal thresholds showed that
τBGopt and
τFGopt are strongly correlated with
FPRBGS and
TPRBGS (see Figure
2↓).
This led us to define the heuristics:
These heuristics may be useful in practice for a BGS user who has access to the performance specifications of a BGS algorithm and hopes for good results without any time-consuming optimization process. Note that, as the BGS classifier performs better than a random classifier, we have
FPRBGS < TPRBGS, which leads to
τBGheu < τFGheu given
(6↑). The heuristics therefore guarantee that don’t-care situations of Table
1↑ cannot be encountered.
(3) Default policy. A more simple alternative consists to set the pair
(τBG,τFG) to default values, such as the mean optimal thresholds of the 5 best BGS algorithms (according to the ranking of CDNet 2014), that is:
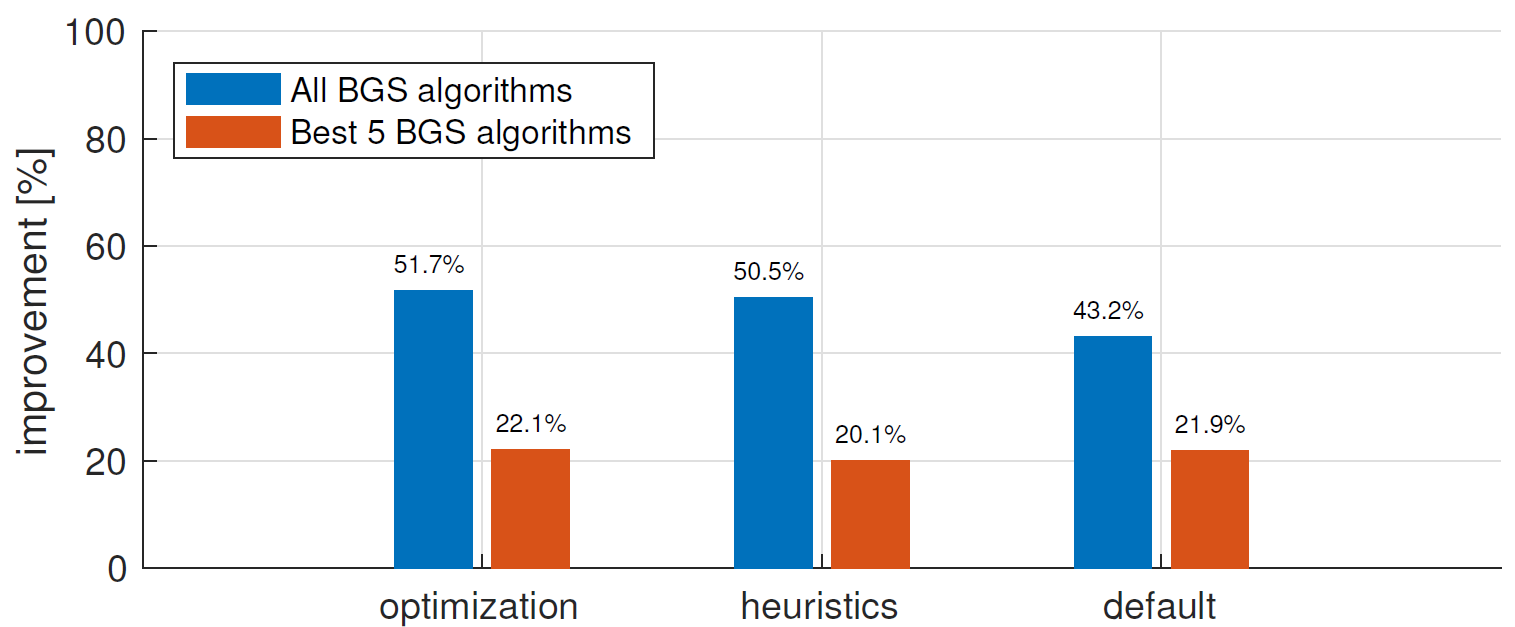
Figure
3↑ presents the improvement on the overall CDNet dataset for the three parameter setting policies. The three policies lead to very similar improvements and allow to reduce the mean overall
ER of the best 5 BGS algorithms by more than
20%. Considering all BGS algorithms, we manage to reduce the mean overall
ER by approximately
50%. Figure
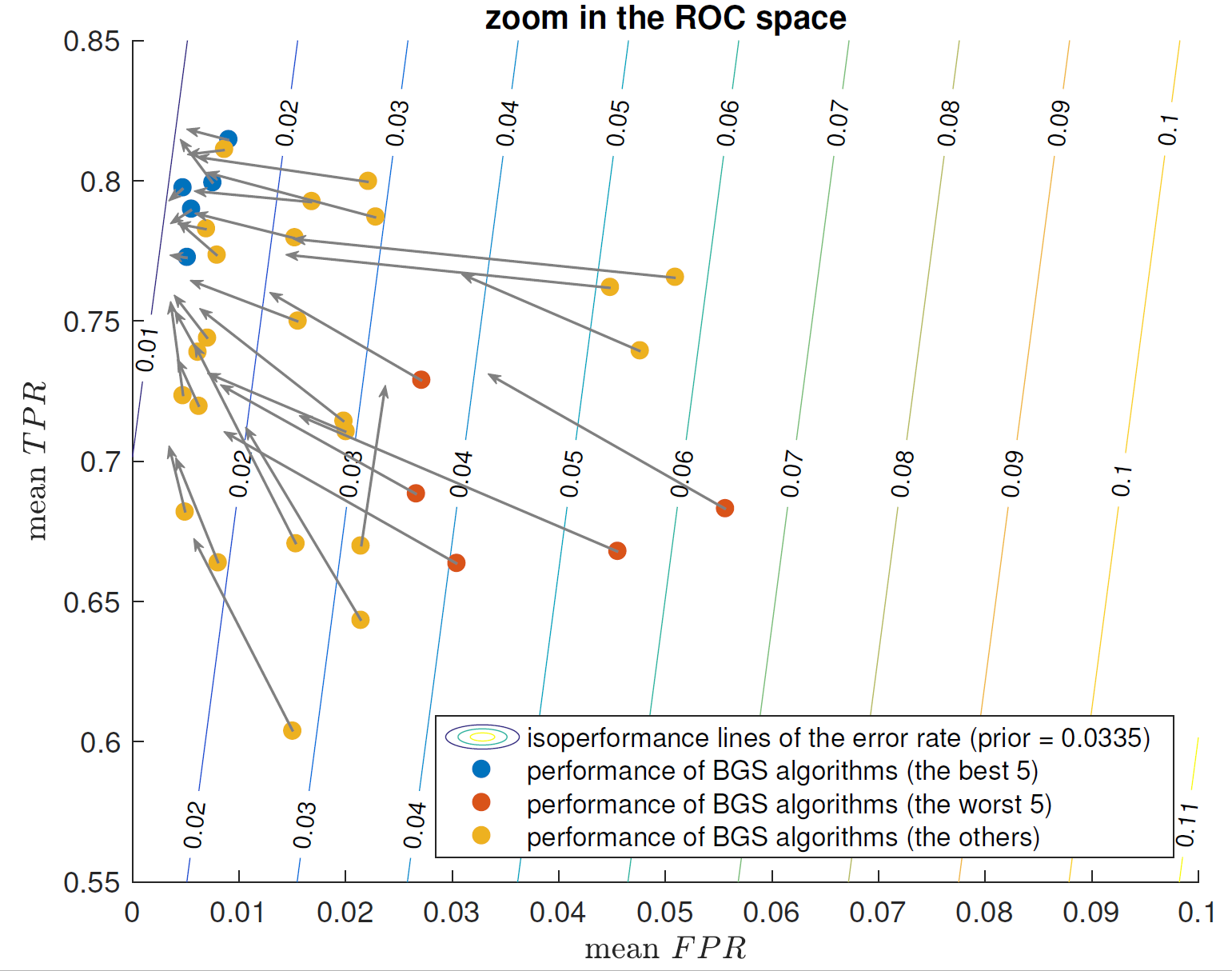
4↓ shows that our framework tends to reduce significantly the
FPR of BGS algorithms, while increasing simultaneously their
TPR.
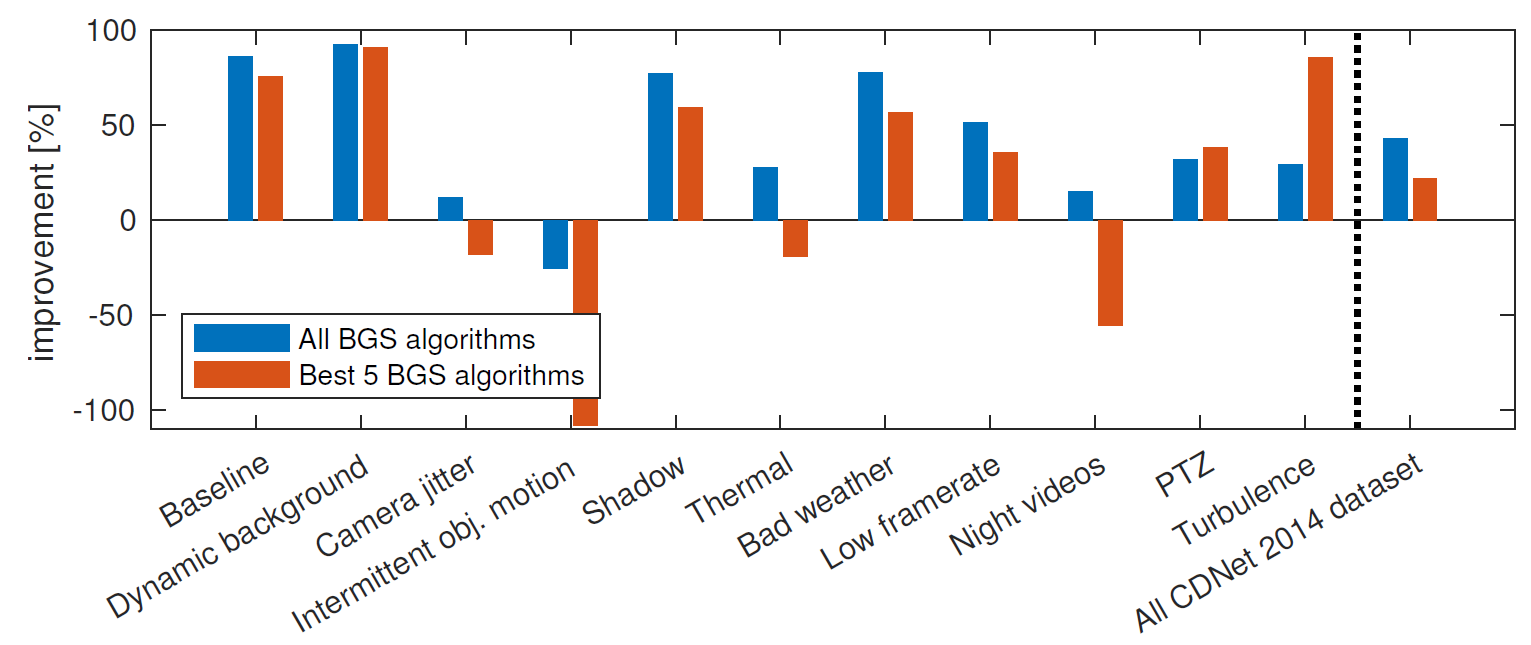
Per-category improvements are detailed in Figure
6↓. We observe huge improvements for “Baseline”, “Dynamic background”, “Shadow”, and “Bad weather” categories. Note that images from the “Thermal” and “Night videos” categories differ completely from natural images of the ADE20K dataset
[2], used to train the semantic segmentation algorithm, which probably explains the lower improvements obtained for those categories.
Figure
5↓ illustrates the benefits of our semantic background subtraction framework for several challenging scenarios of real-world video sequences. It reduces drastically the number of false positive detections caused by dynamic backgrounds, ghosts, and strong shadows, while mitigating simultaneously color camouflage effects.
The consequence for these detection improvements is the computational overhead introduced by the semantic segmentation algorithm. The PSPNet model
[6] used in our experiments runs at approximately 7 frames per second for
473 × 473 image resolution on a NVIDIA GeForce GTX Titan X GPU. However, it is possible to exploit the temporal stability of semantics in the video to reduce the computational load of the semantic segmentation, as done in
[4]. Note that the computational load of
(1↑),
(2↑) and
(3↑) is negligible compared to the computational load of semantic segmentation.
4 Conclusion
We have presented a novel framework for motion detection in videos that combines background subtraction (BGS) algorithms with two signals derived from object-level semantics extracted by semantic segmentation. The framework is simple and universal, i.e. applicable to every BGS algorithm, because it only requires binary segmentation maps. Experiments led on the CDNet dataset show that we managed to improve significantly the performances of 34 BGS algorithms, by reducing their mean overall error rate by roughly 50%.
Acknowledgments. Marc Braham has a grant funded by the FRIA. We are grateful to Hengshuang Zhao for publishing his PSPNet model
[6] on the Internet. The
GeForce GTX Titan X GPU used for this research was donated by the NVIDIA Corporation.
References
[1] : PASCAL VOC Challenge performance evaluation and download server.
[2] B. Zhou, H. Zhao, X. Puig, S. Fidler, A. Barriuso, A. Torralba: “Semantic understanding of scenes through the ADE20K dataset”, CoRR, 2016.
[3] C. Stauffer, E. Grimson: “Adaptive background mixture models for real-time tracking”, IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), pp. 246-252, 1999.
[4] E. Shelhamer, K. Rakelly, J. Hoffman, T. Darrell: “Clockwork Convnets for Video Semantic Segmentation”, European Conference on Computer Vision Workshops (ECCV Workshops), pp. 852-868, 2016.
[5] H. Zhao, J. Shi, X. Qi, X. Wang, J. Jia: “Pyramid Scene Parsing Network”, IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), 2017.
[6] H. Zhao: PSPNet50 ADE20K caffemodel.
[7] H. Zhao: Pyramid Scene Parsing Network.
[8] J. Long, E. Shelhamer, T. Darrell: “Fully Convolutional Networks for Semantic Segmentation”, IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), pp. 3431-3440, 2015.
[9] L. Sevilla-Lara, D. Sun, V. Jampani, M. J. Black: “Optical Flow with Semantic Segmentation and Localized Layers”, IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), pp. 3889-3898, 2016.
[10] M. Braham, A. Lejeune, M. Van Droogenbroeck: “A physically motivated pixel-based model for background subtraction in 3D images”, IEEE International Conference on 3D Imaging (IC3D), pp. 1-8, 2014.
[11] M. Chen, Q. Yang, Q. Li, G. Wang, M.-H. Yang: “Spatiotemporal Background Subtraction Using Minimum Spanning Tree and Optical Flow”, European Conference on Computer Vision (ECCV), pp. 521-534, 2014.
[12] O. Barnich, M. Van Droogenbroeck: “ViBe: A universal background subtraction algorithm for video sequences”, IEEE Transactions on Image Processing, pp. 1709-1724, 2011.
[13] P.-M. Jodoin, S. Piérard, Y. Wang, M. Van Droogenbroeck: Overview and Benchmarking of Motion Detection Methods in Background Modeling and Foreground Detection for Video Surveillance. Chapman and Hall/CRC, 2014.
[14] S. Bianco, G. Ciocca, R. Schettini: “How Far Can You Get By Combining Change Detection Algorithms?”, CoRR, 2015.
[15] S. Piérard, M. Van Droogenbroeck: “A perfect estimation of a background image does not lead to a perfect background subtraction: analysis of the upper bound on the performance”, International Conference on Image Analysis and Processing (ICIAP), Workshop on Scene Background Modeling and Initialization (SBMI), pp. 527-534, 2015.
[16] S. Zhang, H. Yao, S. Liu: “Dynamic background modeling and subtraction using spatio-temporal local binary patterns”, IEEE International Conference on Image Processing (ICIP), pp. 1556-1559, 2008.
[17] S. Zheng, S. Jayasumana, B. Romera-Paredes, V. Vineet, Z. Su, D. Du, C. Huang, P. Torr: “Conditional Random Fields as Recurrent Neural Networks”, International Conference on Computer Vision (ICCV), pp. 1529-1537, 2015.
[18] T. Bouwmans, C. Silva, C. Marghes, M. Zitouni, H. Bhaskar, C. Frelicot: “On the Role and the Importance of Features for Background Modeling and Foreground Detection”, CoRR, pp. 1-131, 2016.
[19] T. Bouwmans: “Traditional and recent approaches in background modeling for foreground detection: An overview”, Computer Science Review, pp. 31-66, 2014.
[20] V. Jain, B. Kimia, J. Mundy: “Background Modeling Based on Subpixel Edges”, IEEE International Conference on Image Processing (ICIP), pp. 321-324, 2007.
[21] Y. Wang, P.-M. Jodoin, F. Porikli, J. Konrad, Y. Benezeth, P. Ishwar: “CDnet 2014: An Expanded Change Detection Benchmark Dataset”, IEEE International Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pp. 393-400, 2014.