Marc Van Droogenbroeck
In Fourth IEEE Benelux Signal Processing,
Hilvarenbeek, The Netherlands,
pages 11-15,
April 2004.
![]()
Keywords:
Image processing,
Information,
Encryption.
[bibtex-entry]
Marc Van Droogenbroeck
In Fourth IEEE Benelux Signal Processing,
Hilvarenbeek, The Netherlands,
pages 11-15,
April 2004.
![]()
Keywords:
Image processing,
Information,
Encryption.
[bibtex-entry]
Hiding the content of a message when it enters an insecure channel should be common practice. Unfortunately none of the audio-visual compression standards includes any mechanism to convert part of the bitstream into ciphertext prior to transmission.
The encryption process requires an encryption algorithm and a key. The process of recovering plaintext from ciphertext is called decryption. The accepted view amongst cryptographers is that the encryption algorithm should be published, whereas the key must be kept secret (KERKHOFF's law). In practice, the distribution of keys is difficult since keys should be exchanged only when a trusted channel has been established. Furthermore for real-time video systems there are other issues to be addressed: speed, compression efficiency, and flexibility.
Speed depends on the encryption algorithm, and on the type of information that is processed. In real-time video transmission, there are basically two strategies depending on wether or not compression takes place before encryption, since we may assume that compression and encryption are both unavoidable. Compression applied first reduces the bitstream but it offers less secrecy. On the other hand if encryption is applied first, compression is ineffective.
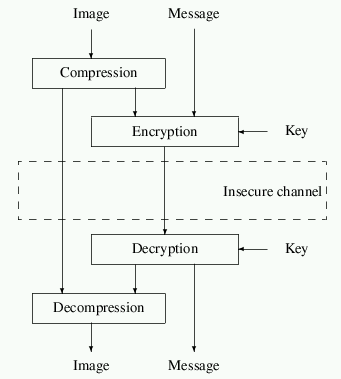
Fortunately there exists an alternative called selective encryption that works as depicted in Figure 1 and is the main topic of this paper.
The image is first compressed and only parts of the bitstream are encrypted.An interesting additional feature for real time applications is the ability to use any decoder, even if parts of the bitstream have been encrypted. If bitstream compatibility is targeted, the bitstream should only be altered at places where it does not compromise the compliance to the original format.
Many algorithms for selective encryption have been proposed but they usually require a proprietary decoder which is unsuitable in the field of video transmission where ISO standards dominates the market.
In the middle of the 90s there have been several papers on the selective encryption of MPEG streams. MAPLES et al. [2] proposed an algorithm which encrypts only the Intra (I) frames of an MPEG stream. However AGI et al. [3] reported that the selective encryption of the I frames only offers a limited level of security, due mainly to the presence of blocks coded in intra mode in P or B frames, but also to the high correlation of P and B frames when they correspond to the same I frame. This scheme is subject to cryptanalysis, a common problem when compression occurs prior to encryption.
Alternative encryption techniques were developed by other authors. In particular, several techniques have been proposed for the encryption of DCT based coded image. A method called zig-zag permutation was originated by TANG [4]. Although this scheme offers more security, it increases the overall bit rate.
Another algorithm, developed by QIAO and NAHRSTEDT, is based on the frequency distribution of pairs of two adjacent bytes in an MPEG bitstream [5]. As proven by the authors, this algorithm provides overall security, and size preservation, but does not meet the requirements of visual acceptance and bitstream compliance.
Other methods have been proposed recently (see [6] for a recent view) but they fail to achieve all of the following requirements:
Because of its widespread use, MPEG was the primary focus for selective encryption. But since MPEG-2 was developed with video broadcasting in mind, selective encryption of MPEG streams will rely on an efficient mechanism for key distribution. An additional difficulty results from the high correlation between frames. MPEG-2 removes many redundancies contained in a video stream but an encoder leaves a residual correlation that affects secrecy and eases cryptanalysis.
Therefore we concentrate on the JPEG standard which is more likely to be used in point to point transmission.
The method described hereafter was first proposed in [1]. We will discuss extensions in Section 3.
In JPEG, the HUFFMAN coder aggregates zero coefficients into runs of zeros. In order to approach the entropy, it also uses symbols that combine the run of zeros with magnitude categories for the non-zero coefficients that terminate the runs. 8-bit code words are assigned by the HUFFMAN coder to these symbols. These code words are followed by appended bits that fully specify the sign and magnitude of the non-zero coefficients. We decided to leave the code words but to encrypt the appended bits. The reasons are that code words are essential for synchronization and that it does not make much sense to replace zero coefficients by non-zero coefficients. Therefore it is essential to preserve the run values. Also, it is not effective to encrypt DC coefficients because they carry important visible information and are highly predictable. Our algorithm encrypts appended bits corresponding to a selected number of AC coefficients. This set of coefficients is the same for each DCT block.
If there is a single copyright owner, called owner hereafter, he will apply the selective DCT encryption algorithm to a subset C1 of coefficients of the JPEG image f with a key k1. The resulting image is g = Ek1(f ).
At the receiver side the decryption algorithm D is able to recompute f if and only if k1 is known: f = Dk1(Ek1(f )). Alternatively we could have used an encryption technique based on a public key and a private key since our technique can accommodate any encryption process.
If there is a second owner, he should be able to choose a subset C2 of DCT coefficients and to encrypt them with his own key k2 as well. The image sent over the network is then h = Ek2(Ek1(f )). We named this principle ``multiple selective encryption'' when C1and C2 are chosen independently.
When C1 intersects with C2 (C1∩C2≠∅), coefficients encrypted twice are more sensitive to attacks and it is recommended to use a technique called over-encryption, that corresponds to Ek1(Dk2(Ek1(f ))), as proposed by TUCHMAN [9]. According to SCHNEIER [10], over-encryption offers better performances than Ek2(Ek1(f )).
 |
 |
| (a) Original image |
(b) Encrypted by owner 1 |
 |
 |
| (c) Encrypted by owner 2 |
(d) Locally encrypted image |
In a generalized scheme we may want to provide:
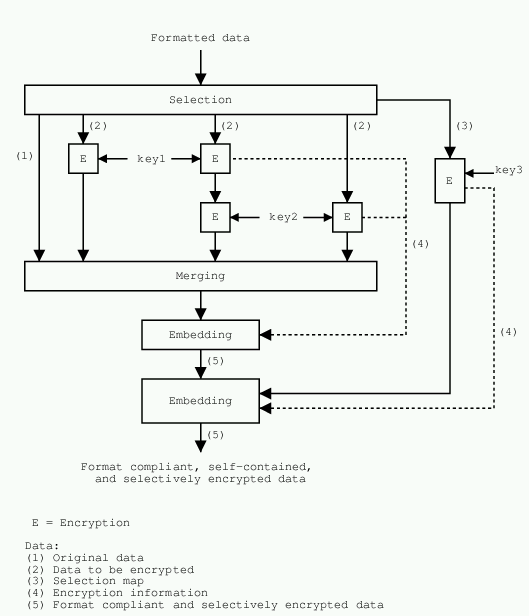
Data is split into several slices. Some slices are left unmodified (this is referred to as part (1) on Figure 3) while other slices (2) are processed by encryption blocks ordered into a sequence S. Slices are encrypted by known algorithms (RSA, Rijndael, etc) with different keys. Note that all encryption blocks may be different. However if a slice is encrypted twice with a similar algorithm, it should be over-encrypted.
The encryption sequence S and the selection map, which states which slice is encoded, used by each encryptor have to be known to the decoder or otherwise specified into a information stream I1, itself encrypted into I2. The type of algorithms has to be known or provided into a stream I3 as well.
All data, whether encrypted or not, are then reassembled into a format compliant stream. As far as merging is concerned, the amounts of bits prior to and after encryption are the same. Since encrypted slices are put in place of the original data and the number of encrypted bits is low, substitution is fast to accommodate to speed requirements of real-time processing.
After merging, there follows 2 embedding steps.
In this paper, we propose a generalized scheme to selectively encrypt an image. The scheme offers several advantages: flexibility, multiplicity, spatial selectively and format compliance. Secrecy results from a tradeoff between processing power and speed, but real-time processing is achievable.
The author is grateful to Hugues TALBOT for his comments.