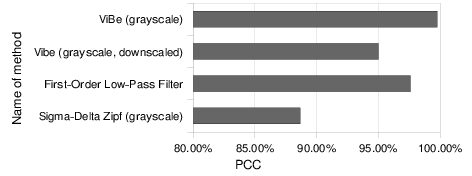ViBe: A universal background subtraction algorithm for video sequences
Olivier Barnich and Marc Van Droogenbroeck
PDF version of this document
 and BiBTeX file
and BiBTeX file 
Code and programs (windows, linux) + source code in C/C++
Executive summary, examples, etc.
Abstract
This paper presents a technique for motion detection that incorporates several innovative mechanisms. For example, our proposed technique stores, for each pixel, a set of values taken in the past at the same location or in the neighborhood. It then compares this set to the current pixel value in order to determine whether that pixel belongs to the background, and adapts the model by choosing randomly which values to substitute from the background model. This approach differs from those based on the classical belief that the oldest values should be replaced first. Finally, when the pixel is found to be part of the background, its value is propagated into the background model of a neighboring pixel.
We describe our method in full details (including pseudo-code and the parameter values used) and compare it to other background subtraction techniques. Efficiency figures show that our method outperforms recent and proven state-of-the-art methods in terms of both computation speed and detection rate. We also analyze the performance of a downscaled version of our algorithm to the absolute minimum of one comparison and one byte of memory per pixel. It appears that even such a simplified version of our algorithm performs better than mainstream techniques. An implementation of ViBe is available at
http://www.telecom.ulg.ac.be/research/vibe.
Background subtraction, surveillance, video signal processing, learning (artificial intelligence), image segmentation, vision and scene understanding, computer vision, image motion analysis, pixel classification, real-time systems.
1 Introduction
The number of cameras available worldwide has increased dramatically over the last decade. But this growth has resulted in a huge augmentation of data, meaning that the data are impossible either to store or to handle manually. In order to detect, segment, and track objects automatically in videos, several approaches are possible. Simple motion detection algorithms compare a static background frame with the current frame of a video scene, pixel by pixel. This is the basic principle of background subtraction, which can be formulated as a technique that builds a model of a background and compares this model with the current frame in order to detect zones where a significant difference occurs. The purpose of a background subtraction algorithm is therefore to distinguish moving objects (hereafter referred to as the foreground) from static, or slow moving, parts of the scene (called background). Note that when a static object starts moving, a background subtraction algorithm detects the object in motion as well as a hole left behind in the background (referred to as a ghost). Clearly a ghost is irrelevant for motion interpretation and has to be discarded. An alternative definition for the background is that it corresponds to a reference frame with values visible most of the time, that is with the highest appearance probability, but this kind of framework is not straightforward to use in practice.
While a static background model might be appropriate for analyzing short video sequences in a constrained indoor environment, the model is ineffective for most practical situations; a more sophisticated model is therefore required. Moreover, the detection of motion is often only a first step in the process of understanding the scene. For example, zones where motion is detected might be filtered and characterized for the detection of unattended bags, gait recognition, face detection, people counting, traffic surveillance, etc. The diversity of scene backgrounds and applications explains why countless papers discuss issues related to background subtraction.
In this paper, we present a universal method for background subtraction. This method has been briefly described in
[48] and in a patent
[45]. In Section
2↓, we extensively review the literature of background subtraction algorithms. This review presents the major frameworks developed for background subtraction and highlights their respective advantages. We have implemented some of these algorithms in order to compare them with our method. Section
3↓ describes our technique and details our major innovations: the background model, the initialization process, and the update mechanism. Section
4↓ discusses experimental results including comparisons with other state-of-the-art algorithms and computational performance. We also present a simplified version of our algorithm which requires only one comparison and one byte of memory per pixel; this is the absolute minimum in terms of comparisons and memory for any background subtraction technique. We show that, even in its simplified form, our algorithm performs better than more sophisticated techniques. Section
5↓ concludes the paper.
2 Review of background subtraction algorithms
The problem tackled by background subtraction techniques involves the comparison of an observed image with an estimated image that does not contain any object of interest; this is referred to as the background model (or background image)
[9]. This comparison process, called
foreground detection, divides the observed image into two complementary sets of pixels that cover the entire image: (1) the foreground that contains the objects of interest, and (2) the background, its complementary set. As stated in
[57], it is difficult to specify a gold-standard definition of what a background subtraction technique should detect as a foreground region, as the definition of foreground objects relates to the application level.
Many background subtraction techniques have been proposed with as many models and segmentation strategies, and several surveys are devoted to this topic (see for example
[64, 59, 9, 8, 57, 24, 60]). Some algorithms focus on specific requirements that an ideal background subtraction technique could or should fulfill. According to
[12], a background subtraction technique must adapt to gradual or fast illumination changes (changing time of day, clouds, etc), motion changes (camera oscillations), high frequency background objects (e.g. tree leave or branches), and changes in the background geometry (e.g. parked cars). Some applications require background subtraction algorithms to be embedded in the camera, so that the computational load becomes the major concern. For the surveillance of outdoor scenes, robustness against noise and adaptivity to illumination changes are also essential.
Most techniques described in the literature operate on each pixel independently. These techniques relegate entirely to post-processing algorithms the task of adding some form of spatial consistency to their results. Since perturbations often affect individual pixels, this results in local misclassifications. By contrast, the method described by Seiki
et al. in
[43] is based on the assumption that neighboring blocks of background pixels should follow similar variations over time. While this assumption holds most of the time, especially for pixels belonging to the same background object, it becomes problematic for neighboring pixels located at the border of multiple background objects. Despite this inconvenience, pixels are aggregated into blocks and each
N × N block is processed as an
N²-component vector. A few samples are then collected over time and used to train a Principal Component Analysis (PCA) model for each block. A block of a new video frame is classified as background if its observed image pattern is close to its reconstructions using PCA projection coefficients of 8-neighboring blocks. Such a technique is also described in
[51], but it lacks an update mechanism to adapt the block models over time. In
[47], the authors focus on the PCA reconstruction error. While the PCA model is also trained with time samples, the resulting model accounts for the whole image. Individual pixels are classified as background or foreground using simple image difference thresholding between the current image and the backprojection in the image space of its PCA coefficients. As for other PCA-based methods, the initialization process and the update mechanism are not described.
A similar approach, the Independent Component Analysis (ICA) of serialized images from a training sequence, is described in
[25] in the training of an ICA model. The resulting de-mixing vector is then computed and compared to that of a new image in order to separate the foreground from a reference background image. The method is said to be highly robust to indoor illumination changes.
A two-level mechanism based on a classifier is introduced in
[28]. A classifier first determines whether an image block belongs to the background. Appropriate blockwise updates of the background image are then carried out in the second stage, depending on the results of the classification. Classification algorithms are also the basis of other algorithms, as in the one provided in
[41], where the background model learns its motion patterns by self organization through artificial neural networks.
Algorithms based on the framework of compressive sensing perform background subtraction by learning and adapting a low dimensional compressed representation of the background
[61]. The major advantage of this approach lies in the fact that compressive sensing estimates object silhouettes without any auxiliary image reconstruction. On the other hand, objects in the foreground need to occupy only a small portion of the camera view in order to be detected correctly.
Background subtraction is considered to be a sparse error recovery problem in
[42]. These authors assumed that each color channel in the video can be independently modeled as the linear combination of the same color channel from other video frames. Consequently, the method they proposed is able to accurately compensate for global changes in the illumination sources without altering the general structure of the frame composition by finding appropriate scalings for each color channel separately.
Background estimation is formulated in
[58] as an optimal labeling problem in which each pixel of the background image is labeled with a frame number, indicating which color from the past must be copied. The author’s proposed algorithm produces a background image, which is constructed by copying areas from the input frames. Impressive results are shown for static backgrounds but the method is not designed to cope with objects moving slowly in the background, as its outcome is a single static background frame.
The authors of
[62] were inspired by the biological mechanism of motion-based perceptual grouping. They propose a spatio-temporal saliency algorithm applicable to scenes with highly dynamic backgrounds, which can be used to perform background subtraction. Comparisons of their algorithm with other state-of-the-art techniques show that their algorithm reduces the average error rate, but at a cost of a prohibitive processing time (several seconds per frame), which makes it unsuitable for real-time applications.
Pixel-based background subtraction techniques compensate for the lack of spatial consistency by a constant updating of their model parameters. The simplest techniques in this category are the use of a static background frame (which has recently been used in
[44]), the (weighted) running average
[1], first-order low-pass filtering
[3], temporal median filtering
[55, 14], and the modeling of each pixel with a gaussian
[30, 32, 19].
Probabilistic methods predict the short-term evolution of a background frame with a Wiener
[37] or a Kalman
[22] filter. In
[37], a frame-level component is added to the pixel-level operations. Its purpose is to detect sudden and global changes in the image and to adapt the background frame accordingly. Median and gaussian models can be combined to allow inliers (with respect to the median) to have more weight than outliers during the gaussian modeling, as in
[31] or
[16]. A method for properly initializing a gaussian background model from a video sequence in which moving objects are present is proposed in
[21].
The
W4 model presented in
[29] is a rather simple but nevertheless effective method. It uses three values to represent each pixel in the background image: the minimum and maximum intensity values, and the maximum intensity difference between consecutive images of the training sequence. The authors of
[33] bring a small improvement to the
W4 model together with the incorporation of a technique for shadow detection and removal.
Methods based on
Σ − Δ (sigma-delta) motion detection filters
[7, 6, 8] are popular for embedded processing
[39, 38]. As in the case of analog-to-digital converters, a
Σ − Δ motion detection filter consists of a simple non-linear recursive approximation of the background image, which is based on comparison and on an elementary increment/decrement (usually
− 1, 0, and
1 are the only possible updating values). The
Σ − Δ motion detection filter is therefore well suited to many embedded systems that lack a floating point unit.
All these unimodal techniques can lead to satisfactory results in controlled environments while remaining fast, easy to implement, and simple. However, more sophisticated methods are necessary when dealing with videos captured in complex environments where moving background, camera egomotion, and high sensor noise are encountered
[64].
Over the years, increasingly complex pixel-level algorithms have been proposed. Among these, by far the most popular is the Gaussian Mixture Model (GMM)
[17, 18]. First presented in
[17], this model consists of modeling the distribution of the values observed over time at each pixel by a weighted mixture of gaussians. This background pixel model is able to cope with the multimodal nature of many practical situations and leads to good results when repetitive background motions, such as tree leaves or branches, are encountered. Since its introduction, the model has gained vastly in popularity among the computer vision community
[13, 49, 51, 57, 67, 66], and it is still raising a lot of interest as authors continue to revisit the method and propose enhanced algorithms
[49, 34, 50, 23, 54, 69]. In
[15], a particle swarm optimization method is proposed to automatically determine the parameters of the GMM algorithm. The authors of
[52] combine a GMM model with a region-based algorithm based on color histograms and texture information. In their experiments, the authors’ method outperform the original GMM algorithm. However, the authors’ technique has a considerable computational cost as they only manage to process seven frames of
640 × 480 pixels per second with an Intel Xeon 5150 processor.
The downside of the GMM algorithm resides in its strong assumptions that the background is more frequently visible than the foreground and that its variance is significantly lower. None of this is valid for every time window. Furthermore, if high- and low-frequency changes are present in the background, its sensitivity cannot be accurately tuned and the model may adapt to the targets themselves or miss the detection of some high speed targets, as detailed in
[4]. Also, the estimation of the parameters of the model (especially the variance) can become problematic in real-world noisy environments. This often leaves one with no other choice than to use a fixed variance in a hardware implementation. Finally, it should be noted that the statistical relevance of a gaussian model is debatable as some authors claim that natural images exhibit non-gaussian statistics
[12].
To avoid the difficult question of finding an appropriate shape for the probability density function, some authors have turned their attention to non-parametric methods to model background distributions. One of the strengths of non-parametric kernel density estimation methods
[4, 5, 10, 65, 68, 69] is their ability to circumvent a part of the delicate parameter estimation step due to the fact that they rely on pixel values observed in the past. For each pixel, these methods build a histogram of background values by accumulating a set of real values sampled from the pixel’s recent history. These methods then estimate the probability density function with this histogram to determine whether or not a pixel value of the current frame belongs to the background. Non-parametric kernel density estimation methods can provide fast responses to high-frequency events in the background by directly including newly observed values in the pixel model. However, the ability of these methods to successfully handle concomitant events evolving at various speeds is questionable since they update their pixel models in a first-in first-out manner. This has led some authors to represent background values with two series of values or models: a short term model and a long term model
[4, 26]. While this can be a convenient solution for some situations, it leaves open the question of how to determine the proper time interval. In practical terms, handling two models increases the difficulty of fine-tuning the values of the underlying parameters. Our method incorporates a smoother lifespan policy for the sampled values, and as explained in Section
4↓, it improves the overall detection quality significantly.
In the codebook algorithm
[35, 36], each pixel is represented by a codebook, which is a compressed form of background model for a long image sequence. Each codebook is composed of codewords comprising colors transformed by an innovative color distortion metric. An improved codebook incorporating the spatial and temporal context of each pixel has been proposed in
[46]. Codebooks are believed to be able to capture background motion over a long period of time with a limited amount of memory. Therefore, codebooks are learned from a typically long training sequence and a codebook update mechanism is described in
[36] allowing the algorithm to evolve with the lighting conditions once the training phase is over. However, one should note that the proposed codebook update mechanism does not allow the creation of new codewords, and this can be problematic if permanent structural changes occur in the background (for example, in the case of newly freed parking spots in urban outdoor scenes).
Instead of choosing a particular form of background density model, the authors of
[63, 27] use the notion of “consensus”. They keep a cache of a given number of last observed background values for each pixel and classify a new value as background if it matches most of the values stored in the pixel’s model. One might expect that such an approach would avoid the issues related to deviations from an arbitrarily assumed density model, but since values of pixel models are replaced according to a first-in first-out update policy, they are also prone to the problems discussed previously, for example, the problem of slow and fast motions in the background, unless a large number of pixel samples are stored. The authors state that a cache of 20 samples is the minimum required for the method to be useful, but they also noticed no significant further improvement for caches with more than 60 samples. Consequently, the training period for their algorithm must comprise at least 20 frames. Finally, to cope with lighting changes and objects appearing or fading in the background, two additional mechanisms (one at the pixel level, a second at the blob level) are added to the consensus algorithm to handle entire objects.
The method proposed in this paper operates differently in handling new or fading objects in the background, without the need to take account of them explicitly. In addition to being faster, our method exhibits an interesting asymmetry in that a ghost (a region of the background discovered once a static object starts moving) is added to the background model more quickly than an object that stops moving. Another major contribution of this paper resides in the proposed update policy. The underlying idea is to gather samples from the past and to update the sample values by ignoring when they were added to the models. This policy ensures a smooth exponential decaying lifespan for the sample values of the pixel models and allows our technique to deal with concomitant events evolving at various speeds with a unique model of a reasonable size for each pixel.
3 Description of a universal background subtraction technique: ViBe
Background subtraction techniques have to deal with at least three considerations in order to be successful in real applications: (1) what is the model and how does it behave?, (2) how is the model initialized?, and (3) how is the model updated over time? Answers to these questions are given in the three subsections of this section. Most papers describe the intrinsic model and the updating mechanism. Only a minority of papers discuss initialization, which is critical when a fast response is expected, as in the case inside a digital camera. In addition, there is often a lack of coherence between the model and the update mechanism. For example, some techniques compare the current value of a pixel p to that of a model b with a given tolerance T. They consider that there is a good match if the absolute difference between p and b is lower than T. To be adaptive over time, T is adjusted with respect to the statistical variance of p. But the statistical variance is estimated by a temporal average. Therefore, the adjustment speed is dependent on the acquisition framerate and on the number of background pixels. This is inappropriate in some cases, as in the case of remote IP cameras whose framerate is determined by the available bandwidth.
We detail below a background subtraction technique, called “ViBe” (for “VIsual Background Extractor”). For convenience, we present a complete version of our algorithm in a C-like code in Appendix
2↓.
3.1 Pixel model and classification process
To some extent, there is no way around the determination, for a given color space, of a probability density function (pdf) for every background pixel or at least the determination of statistical parameters, such as the mean or the variance. Note that with a gaussian model, there is no distinction to be made as the knowledge of the mean and variance is sufficient to determine the pdf. While the classical approaches to background subtraction and most mainstream techniques rely on pdfs or statistical parameters, the question of their statistical significance is rarely discussed, if not simply ignored. In fact, there is no imperative to compute the pdf as long as the goal of reaching a relevant background segmentation is achieved. An alternative is to consider that one should enhance statistical significance over time, and one way to proceed is to build a model with real observed pixel values. The underlying assumption is that this makes more sense from a stochastic point of view, as already observed values should have a higher probability of being observed again than would values not yet encountered.
Like the authors of
[27], we do not opt for a particular form for the pdf, as deviations from the assumed pdf model are ubiquitous. Furthermore, the evaluation of the pdf is a global process and the shape of a pdf is sensitive to outliers. In addition, the estimation of the pdf raises the non-obvious question regarding the number of samples to be considered; the problem of selecting a representative number of samples is intrinsic to all the estimation processes.
If we see the problem of background subtraction as a classification problem, we want to classify a new pixel value with respect to its immediate neighborhood in the chosen color space, so as to avoid the effect of any outliers. This motivates us to model each background pixel with a set of samples instead of with an explicit pixel model. Consequently no estimation of the pdf of the background pixel is performed, and so the current value of the pixel is compared to its closest samples within the collection of samples. This is an important difference in comparison with existing algorithms, in particular with those of consensus-based techniques. A new value is compared to background samples and should be close to some of the sample values instead of the majority of all values. The underlying idea is that it is more reliable to estimate the statistical distribution of a background pixel with a small number of close values than with a large number of samples. This is somewhat similar to ignoring the extremities of the pdf, or to considering only the central part of the underlying pdf by thresholding it. On the other hand, if one trusts the values of the model, it is crucial to select background pixel samples carefully. The classification of pixels in the background therefore needs to be conservative, in the sense that only background pixels should populate the background models.
Formally, let us denote by
v(x) the value in a given Euclidean color space taken by the pixel located at
x in the image, and by
vi a background sample value with an index
i. Each background pixel
x is modeled by a collection of
N background sample values
taken in previous frames. For now, we ignore the notion of time; this is discussed later.
To classify a pixel value
v(x) according to its corresponding model
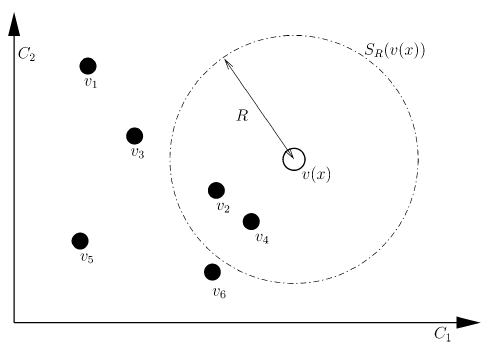
ℳ(x), we compare it to the
closest values within the set of samples by defining a sphere
SR(v(x)) of radius
R centered on
v(x). The pixel value
v(x) is then classified as background if the cardinality, denoted
♯, of the set intersection of this sphere and the collection of model samples
ℳ(x) is larger than or equal to a given threshold
♯min. More formally, we compare
♯min to
According to equation
2↑, the classification of a pixel value
v(x) involves the computation of
N distances between
v(x) and model samples, and of
N comparison with a thresholded Euclidean distance
R. This process is illustrated in Figure
1↓. Note that, as we are only interested in finding a few matches, the segmentation process of a pixel can be stopped once
♯min matches have been found.
As can easily be seen, the accuracy of our model is determined by two parameters only: the radius
R of the sphere and the minimal cardinality
♯min. Experiments have shown that a unique radius R of 20 (for monochromatic images) and a cardinality of 2 are appropriate (see Section
4.1↓ for a thorough discussion on parameter values). There is no need to adapt these parameters during the background subtraction nor do we need to change them for different pixel locations within the image. Note that since the number of samples
N and
♯min are chosen to be fixed and since they impact on the same decision, the sensitivity of the model can be adjusted using the following ratio
but in all our comparative tests we kept these values unchanged.
So far we have detailed the nature of the model. In the coming sections, we explain how to initialize the model from a single frame and how to update it over time.
3.2 Background model initialization from a single frame
Many popular techniques described in the literature, such as
[4],
[36], and
[27], need a sequence of several dozens of frames to initialize their models. Such an approach makes sense from a statistical point of view as it seems imperative to gather a significant amount of data in order to estimate the temporal distribution of the background pixels. But one may wish to segment the foreground of a sequence that is even shorter than the typical initialization sequence required by some background subtraction algorithms. Furthermore, many applications require the ability to provide an
uninterrupted foreground detection, even in the presence of sudden light changes, which cannot be handled properly by the regular update mechanism of the algorithm. A possible solution to both these issues is to provide a specific model update process that tunes the pixel models to new lighting conditions. But the use of such a dedicated update process is at best delicate, since a sudden illumination may completely alter the chromatic properties of the background.
A more convenient solution is to provide a technique that will initialize the background model from a single frame. Given such a technique, the response to sudden illumination changes is straightforward: the existing background model is discarded and a new model is initialized instantaneously. Furthermore, being able to provide a reliable foreground segmentation as early on as the second frame of a sequence has obvious benefits for short sequences in video-surveillance or for devices that embed a motion detection algorithm.
Since there is no temporal information in a single frame, we use the same assumption as the authors of
[53], which is that neighboring pixels share a similar temporal distribution. This justifies the fact that we populate the pixel models with values found in the spatial neighborhood of each pixel. More precisely, we fill them with values randomly taken in their neighborhood in the first frame. The size of the neighborhood needs to be chosen so that it is large enough to comprise a sufficient number of different samples, while keeping in mind that the statistical correlation between values at different locations decreases as the size of the neighborhood increases. From our experiments, selecting samples randomly in the 8-connected neighborhood of each pixel has proved to be satisfactory for images of
640 × 480 pixels.
Formally, we assume that
t = 0 indexes the first frame and that
NG(x) is a spatial neighborhood of a pixel location
x, therefore
where locations
y are chosen randomly according to a uniform law. Note that it is possible for a given
v0(y) to be selected several times (for example if the size of the neighborhood is smaller than the cardinality of
ℳ0(x)) or to not be selected at all. However, this is not an issue if one acknowledges that values in the neighborhood are excellent sample candidates.
This strategy has proved to be successful. The only drawback is that the presence of a moving object in the first frame will introduce an artifact commonly called a
ghost. According to
[14], a ghost is “a set of connected points, detected as in motion but not corresponding to any real moving object”. In this particular case, the ghost is caused by the unfortunate initialization of pixel models with samples coming from the moving object. In subsequent frames, the object moves and uncovers the real background, which will be learned progressively through the regular model update process, making the ghost fade over time. Fortunately, as shown in Section
4.3↓, our update process ensures both a fast model recovery in the presence of a ghost and a slow incorporation of real moving objects into the background model.
3.3 Updating the background model over time
In this Section, we describe how to continuously update the background model with each new frame. This a crucial step if we want to achieve accurate results over time: the update process must be able to adapt to lighting changes and to handle new objects that appear in a scene.
3.3.1 General discussions on an update mechanism
The classification step of our algorithm compares the current pixel value vtx(#2) directly to the samples contained in the background model of the previous frame, ℳt − 1(x) at time t − 1. Consequently, the question regarding which samples have to be memorized by the model and for how long is essential. One can see the model as a background memory or background history, as it is often referred to in the literature. The classical approach to the updating of the background history is to discard and replace old values after a number of frames or after a given period of time (typically about a few seconds); the oldest values are substituted by the new ones. Despite the rationale behind it, this substitution principle is not so obvious, as there is no reason to remove a valid value if it corresponds to a background value.
The question of including or not foreground pixel values in the model is one that is always raised for a background subtraction method based on samples; otherwise the model will not adapt to changing conditions. It boils down to a choice between a conservative and a blind update scheme. Note that kernel-based pdf estimation techniques have a softer approach to updating. They are able to smooth the appearance of a new value by giving it a weight prior to inclusion.
A conservative update policy never includes a sample belonging to a foreground region in the background model. In practice, a pixel sample can be included in the background model only if it has been classified as a background sample. Such a policy seems, at first sight, to be the obvious choice. It actually guarantees a sharp detection of the moving objects, given that they do not share similar colors with the background. Unfortunately, it also leads to deadlock situations and everlasting ghosts: a background sample incorrectly classified as foreground prevents its background pixel model from being updated. This can keep indefinitely the background pixel model from being updated and could cause a permanent misclassification. Unfortunately, many practical scenarios lead to such situations. For example, the location freed by a previously parked car cannot be included in the background model with a purely conservative update scheme, unless a dedicated update mechanism handles such situations.
Blind update is not sensitive to deadlocks: samples are added to the background model whether they have been classified as background or not. The principal drawback of this method is a poor detection of slow moving targets, which are progressively included in the background model. A possible solution consists of using pixel models of a large size, which cover long time windows. But this comes at the price of both an increased memory usage and a higher computational cost. Furthermore, with a first-in first-out model update policy such as those employed in
[4] or
[27], 300 samples cover a time window of only 10 seconds (at 30 frames per second). A pixel covered by a slowly moving object for more than 10 seconds would still be included in the background model.
Strictly speaking, temporal information is not available when the background is masked. But background subtraction is a spatio-temporal process. In order to improve the technique, we could assume, as we proposed in Section
3.2↑, that neighboring pixels are expected to have a similar temporal distribution. According to this hypothesis, the best strategy is therefore to adopt a conservative update scheme and to exploit spatial information in order to inject information regarding the background evolution into the background pixel models masked locally by the foreground. This process is common in inpainting, where objects are removed and values are taken in the neighborhood to fill holes
[2]. In Section
3.3.4↓, we provide a simple but effective method for exploiting spatial information, which enables us to counter most of the drawbacks of a purely conservative update scheme.
Our update method incorporates three important components: (1) a memoryless update policy, which ensures a smooth decaying lifespan for the samples stored in the background pixel models, (2) a random time subsampling to extend the time windows covered by the background pixel models, and (3) a mechanism that propagates background pixel samples spatially to ensure spatial consistency and to allow the adaptation of the background pixel models that are masked by the foreground. These components are described, together with our reasons for using them, in the following three subsections.
3.3.2 A memoryless update policy
Many sample-based methods use first-in first-out policies to update their models. In order to deal properly with wide ranges of events in the scene background, Wang
et al. [27] propose the inclusion of large numbers of samples in pixel models. But as stated earlier, this may still not be sufficient for high framerates. Other authors
[4, 68] incorporate two temporal sub-models to handle both fast and slow modifications. This approach proved to be effective. However, it increases the parametrization problem, in that it makes necessary to determine a greater number of parameter values in order to achieve a practical implementation.
From a theoretical point of view, we believe that it is more appropriate to ensure a monotonic decay of the probability of a sample value to remain inside the set of samples. A pixel model should contain samples from the recent past of the pixel but older samples should not necessarily be discarded.
We propose a method that offers an exponential monotonic decay for the remaining lifespan of the samples. The method improves the time relevance of the estimation by allowing a few old samples to remain in the pixel model. Remember that this approach is combined with a conservative update policy, so that foreground values should never be included in the models.
The technique, illustrated in Figure
2↓, is simple but effective: instead of systematically removing the oldest sample from the pixel model, we choose the sample to be discarded randomly according to a uniform probability density function.
The new value then replaces the selected sample. This random strategy contradicts the idea that older values should be replaced first, which is not true for a conservative update policy. A conservative update policy is also necessary for the stability of the process. Indeed, the random update policy produces a non-deterministic background subtraction algorithm (to our knowledge, this is the first background subtraction algorithm to have that property). Only a conservative update policy ensures that the models do not diverge over time. Despite this, there may be slight differences, imperceptible in our experience, between the results of the same sequence processed by our background subtraction algorithm at different times.
Mathematically, the probability of a sample present in the model at time
t being preserved after the update of the pixel model is given by
(N − 1)/(N). Assuming time continuity and the absence of memory in the selection procedure, we can derive a similar probability, denoted
P(t, t + dt) hereafter, for any further time
t + dt. This probability is equal to
which can be rewritten as
This expression shows that the expected remaining lifespan of any sample value of the model decays exponentially. It appears that the probability of a sample being preserved for the interval
(t, t + dt), assuming that it was included in the model prior to time
t, is independent of
t. In other words, the past has no effect on the future. This property, called the
memoryless property, is known to be applicable to an exponential density (see
[11]). This is a remarkable and, to our knowledge, unique property in the field of background subtraction. It completely frees us to define a time period for keeping a sample in the history of a pixel and, to some extent, allows the update mechanism to adapt to an arbitrary framerate.
3.3.3 Time subsampling
We have shown how the use of a random replacement policy allow our pixel model to cover a large (theoretically infinite) time window with a limited number of samples. In order to further extend the size of the time window covered by a pixel model of a fixed size, we resort to random time subsampling. The idea is that in many practical situations, it is not necessary to update each background pixel model for each new frame. By making the background update less frequent, we artificially extend the expected lifespan of the background samples. But in the presence of periodic or pseudo-periodic background motions, the use of fixed subsampling intervals might prevent the background model from properly adapting to these motions. This motivates us to use a random subsampling policy. In practice, when a pixel value has been classified as belonging to the background, a random process determines whether this value is used to update the corresponding pixel model.
In all our tests, we adopted a time subsampling factor, denoted φ, of 16: a background pixel value has 1 chance in 16 of being selected to update its pixel model. But one may wish to tune this parameter to adjust the length of the time window covered by the pixel model.
3.3.4 Spatial consistency through background samples propagation
Since we use a conservative update scheme, we have to provide a way of updating the background pixel models that are hidden by the foreground. A popular way of doing this is to use what the authors of the
W4 algorithm
[29] call a “
detection support map” which counts the number of consecutive times that a pixel has been classified as foreground. If this number reaches a given threshold for a particular pixel location, the current pixel value at that location is inserted into the background model. A variant consists of including, in the background, groups of connected foreground pixels that have been found static for a long time, as in
[56]. Some authors, like those of the
W4 algorithm and those of the SACON model
[63, 27], use a combination of a pixel-level and an object-level background update.
The strength of using a conservative update comes from the fact that pixel values classified as foreground are never included in any background pixel model. While convenient, the support map related methods only delay the inclusion of foreground pixels. Furthermore, since these methods rely on a binary decision, it takes time to recover from a improper inclusion of a genuine foreground object in the background model. A progressive inclusion of foreground samples in the background pixel models is more appropriate.
As stated earlier, we have a different approach. We consider that neighboring background pixels share a similar temporal distribution and that a new background sample of a pixel should also update the models of neighboring pixels. According to this policy, background models hidden by the foreground will be updated with background samples from neighboring pixel locations from time to time. This allows a spatial diffusion of information regarding the background evolution that relies on samples classified exclusively as background. Our background model is thus able to adapt to a changing illumination and to structural evolutions (added or removed background objects) while relying on a strict conservative update scheme.
More precisely, let us consider the 4- or 8-connected spatial neighborhood of a pixel x, that is NG(x), and assume that it has been decided to update the set of samples ℳ(x) by inserting v(x). We then also use this value v(x) to update the set of samples ℳ(y ∈ NG(x)) from one of the pixels in the neighborhood, chosen at random according to a uniform law.
Since pixel models contain many samples, irrelevant information that could accidentally be inserted into the neighborhood model does not affect the accuracy of the detection. Furthermore, the erroneous diffusion of irrelevant information is blocked by the need to match an observed value before it can propagate further. This natural limitation inhibits the diffusion of error.
Note that neither the selection policy nor the spatial propagation method is deterministic. As stated earlier, if the algorithm is run over the same video sequence again, the results will always differ slightly (see Figure
2↑). Although unusual, the strategy of allowing a random process to determine which samples are to be discarded proves to be very powerful. This is different from known strategies that introduce a fading factor or that use a long term and a short term history of values.
This concludes the description of our algorithm. ViBe makes no assumption regarding the video stream framerate or color space, nor regarding the scene content, the background itself, or its variability over time. Therefore, we refer to it as a universal method.
4 Experimental results
In this section, we determine optimal values for the parameters of ViBe, and compare its results with those of seven other algorithms: two simple methods and five state-of-the art techniques. We also describe some advantageous and intrinsic properties of ViBe, and finally, we illustrate the suitability of ViBe for embedded systems.
For the sake of comparison, we have produced manually ground-truth segmentation maps for subsets of frames taken from two test sequences. The first sequence (called “house”) was captured outdoor on a windy day. The second sequence (“pets”) was extracted from the PETS2001 public data-set (data-set 3, camera 2, testing). Both sequences are challenging as they feature background motion, moving trees and bushes, and changing illumination conditions. The “pets” sequence is first used below to determine objective values for some of the parameters of ViBe. We then compare ViBe with seven existing algorithms on both sequences.
Many metrics can be used to assess the output of a background subtraction algorithm given a series of ground-truth segmentation maps. These metrics usually involve the following quantities: the number of true positives (TP), which counts the number of correctly detected foreground pixels; the number of false positives (FP), which counts the number of background pixels incorrectly classified as foreground; the number of true negatives (TN), which counts the number of correctly classified background pixels; and the number of false negatives (FN), which accounts for the number of foreground pixels incorrectly classified as background.
The difficulty of assessing background subtraction algorithms originates from the lack of a standardized evaluation framework; some frameworks have been proposed by various authors but mainly with the aim of pointing out the advantages of their own method. According to
[59], the metric most widely used in computer vision to assess the performance of a binary classifier is the Percentage of Correct Classification (PCC), which combines all four values:
This metric was adopted for our comparative tests. Note that the PCC percentage needs to be as high as possible, in order to minimize errors.
4.1 Determination of our own parameters
From previous discussions, it appears that ViBe has the following parameters:
-
the radius R of the sphere used to compare a new pixel value to pixel samples (see equation 2↑),
-
the time subsampling factor φ,
-
the number N of samples stored in each pixel model,
-
and the number ♯min of close pixel samples needed to classify a new pixel value as background (see equation 2↑).
In our experience, the use of a radius R = 20 and a time subsampling factor φ = 16 leads to excellent results in every situation. Note that the use of R = 20 is an educated choice, which corresponds to a perceptible difference in color.
To determine an optimal value for
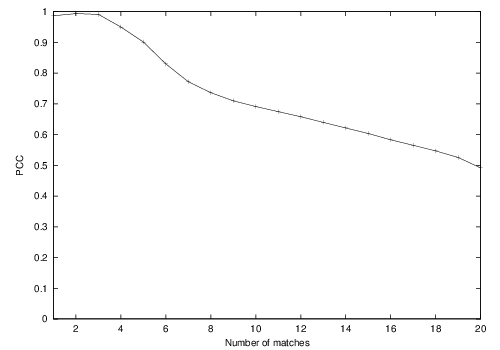
♯min, we compute the evolution of the PCC of ViBe on the “pets” sequence for
♯min ranging from 1 to 20. The other parameters were fixed to
N = 20,
R = 20, and
φ = 16. Figure
3↓ shows that the best PCCs are obtained for
♯min = 2 and
♯min = 3.
Since a rise in ♯min is likely to increase the computational cost of ViBe, we set the optimal value of ♯min to ♯min = 2. Note that in our experience, the use of ♯min = 1 can lead to excellent results in scenes with a stable background.
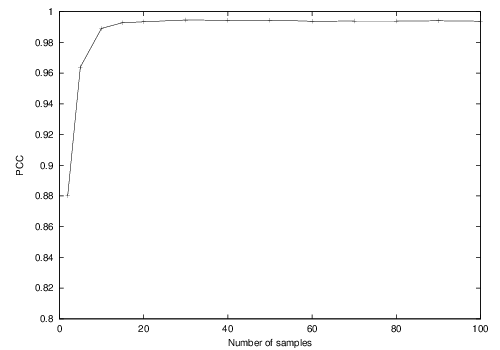
Once the value of 2 has been selected for
♯min, we study the influence of the parameter
N on the performance of ViBe. Figure
4↓ shows percentages obtained on the “pets” sequence for
N ranging from 2 to 50 (
R and
φ were set to 20 and 16).
We observe that higher values of
N provide a better performance. However, they tend to saturate for values higher than
20. Since as for
♯min, large
N values induce a greater computational cost, we select
N at the beginning of the plateau, that is
N = 20.
4.2 Comparison with other techniques
We now compare the results of ViBe with those of five state-of-the-art background subtraction algorithms and two basic methods: (1) the gaussian mixture model proposed in
[50] (hereafter referred to as GMM); (2) the gaussian mixture model of
[69] (referred to as EGMM); (3) the Bayesian algorithm based on histograms introduced in
[40]; (4) the codebook algorithm
[36]; (5) the zipfian
Σ − Δ estimator of
[8]; (6) a single gaussian model with an adaptive variance (named “gaussian model” hereafter); and (7) the first-order low-pass filter (that is
Bt = αIt + (1 − α)Bt − 1, where
It and
Bt are respectively the input and background images at time
t), which is used as a baseline.
The first-order low-pass filter was tested using a fading factor
α of
0.05 and a detection threshold
T of
20. A similar fading factor
α of
0.05 was used for the gaussian model. The GMM of
[40] and the Bayesian algorithm of
[50] were tested using their implementations available in Intel’s IPP image processing library. For the EGMM algorithm of
[69], we used the implementation available on the author’s website. The authors of the zipfian
Σ − Δ filter were kind enough to provide us with their code to test their method. We implemented the codebook algorithm ourselves and used the following parameters:
50 training frames,
λ = 34,
ϵ1 = 0.2,
ϵ2 = 50,
α = 0.4, and
β = 1.2. ViBe was tested with the default values proposed in this paper:
N = 20,
R = 20,
♯min = 2, and
φ = 16. Most of the algorithms were tested using the RGB color space; the codebook uses its own color space, and the
Σ − Δ filter implementation works on grayscale image. In addition, we implemented a grayscale version of ViBe.
Figures
5↓ and
6↓ show examples of foreground detection for one typical frame of each sequence. Foreground and background pixels are shown in white and black respectively.
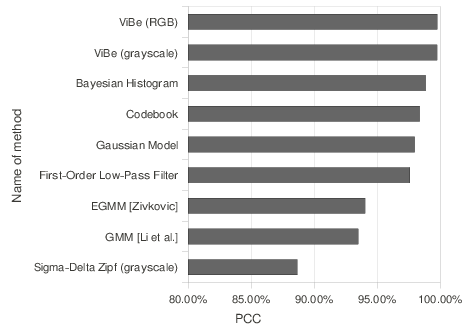
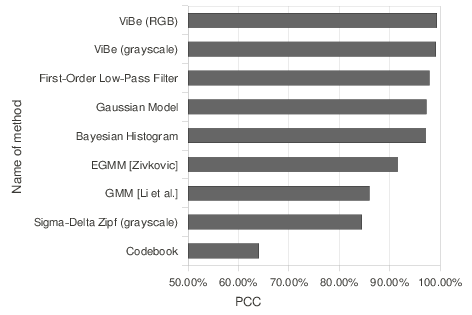
Visually, the results of ViBe look better and are the closest to ground-truth references. This is confirmed by the PCC scores; the PCC scores of the nine comparison algorithms for both sequences are shown in Figure
7↓.
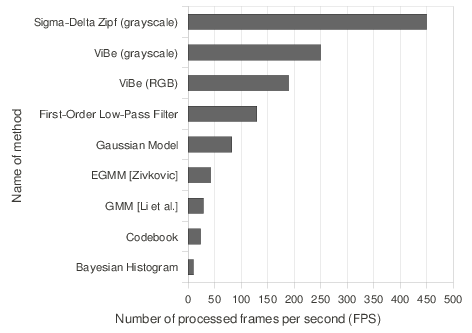
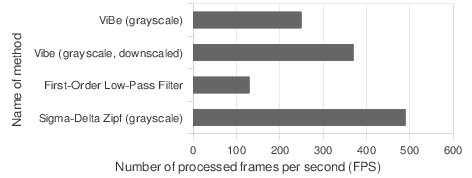
We also compared the computation times of these nine algorithms with a profiling tool, and expressed the computation times in terms of achievable framerates. Figure
8↓ shows their average processing speed on our platform (2.67GHz Core i7 CPU, 6GB of RAM, C implementation).
We did not optimize the code of the algorithms explicitly, except in the case of the Σ − Δ algorithm, which was optimized by its authors, the algorithms of the IPP library (GMM and Bayesian histogram), which are optimized for Intel processors, and ViBe to some extent. To speed up operations involving random numbers in ViBe, we used a buffer pre-filled with random numbers.
We see that ViBe clearly outperforms the seven other techniques: its PCCs are the highest for both sequences and its processing speed is as high as a framerate of 200 frames per second, that is 5 times more than algorithms optimized by Intel. Compare these figures to those obtained by the algorithm proposed by Chiu
et al. [20] recently; they claim to segment
320 × 240 images at a framerate of around
40 frames per second. A simple rescaling to the size of our images lowers this value to
10 frames per second.
The only method faster than ViBe is the zipfian
Σ − Δ estimator, whose PCC is
12 to
15% smaller than that of ViBe. The authors of the zipfian sigma-delta algorithm provided us with post-processed segmentation maps of the “house” sequence which exhibit an improved PCC but a the cost of a lower processing speed. One can wonder how it is possible that ViBe runs faster than simpler techniques such as the first-order filter model. We discuss this question in Appendix
3↓.
In terms of PCC scores, only the Bayesian algorithm of
[40] based on histograms competes with ViBe. However, it is more than 20 times slower than ViBe. As shown in Figures
5↑ and
6↑, the grayscale and the color versions of ViBe manage to combine both a very small rate of FP and a sharp detection of the foreground pixels. The low FP rate of ViBe eliminates the need for any post-processing, which further alleviates the total computational cost of the foreground detection.
Next, we concentrate on the specific strengths of ViBe: fast ghost suppression, intrinsic resilience to camera shake, noise resilience, and suitability for embedding.
4.3 Faster ghost suppression
A background model has to adapt to modifications of the background caused by changing lighting conditions but also to those caused by the addition, removal, or displacement of some of its parts. These events are the principal cause of the appearance of ghosts: regions of connected foreground points that do not correspond to any real object.
When using a detection support map or a related technique to detect and suppress ghosts, it is very hard, if not impossible, to distinguish ghosts from foreground objects that are currently static. As a result, real foreground objects are included in the background model if they remain static for too long. This is a correct behavior since a static foreground object must eventually become part of the background after a given time. It would be better if ghosts were included in the background model more rapidly than real objects, but this is impossible since they cannot be distinguished using a detection support map.
Our spatial update mechanism speeds up the inclusion of ghosts in the background model so that the process is faster than the inclusion of real static foreground objects. This can be achieved because the borders of the foreground objects often exhibit colors that differ noticeably from those of the samples stored in the surrounding background pixel models. When a foreground object stops moving, the information propagation technique described in Section
3.3.4↑ updates the pixel models located at its borders with samples coming from surrounding background pixels. But these samples are irrelevant: their colors do not match at all those of the borders of the object. In subsequent frames, the object remains in the foreground, since background samples cannot diffuse inside the foreground object via its borders.
By contrast, a ghost area often shares similar colors with the surrounding background. When background samples from the area surrounding the ghost try to diffuse inside the ghost, they are likely to match the actual color of the image at the locations where they are diffused. As a result, the ghost is progressively eroded until it disappears entirely. Figure
9↑ illustrates this discussion.
The speed of this process depends on the texture of the background: the faster ghost suppressions are obtained with backgrounds void of edges. Furthermore, if the color of the removed object is close to that of the uncovered background area, the absorption of the ghost is faster.
When needed, the speed of the ghost suppression process can be tuned by adapting the time subsampling factor
φ. For example, in the sequence displayed in Figure
9↑, if we assume a framerate of 30 frames per second, the ghost fades out after 2 seconds for a time subsampling factor
φ equal to 1. However, if we set
φ to 64, it takes 2 minutes for ViBe to suppress the ghost completely. For the sake of comparison, the Bayesian histogram algorithm suppresses the same ghost area in 5 seconds.
One may ask how static foreground objects will ultimately be included in the background model. The responsibility for the absorption of foreground pixels into the background lies with the noise inevitably present in the video sequence. Due to the noise, some pixels of the foreground object end up in the background, and then serve as background seeds. Consequently, their models are corrupted with foreground samples. These samples later diffuse into their neighboring models, as a result of the spatial propagation mechanism of the background samples, and allow a slow inclusion of foreground objects in the background.
4.4 Resistance to camera displacements
In many situations, small displacements of the camera are encountered. These small displacements are typically due to vibrations or wind and, with many other techniques, they cause significant numbers of false foreground detections.
Another obvious benefit of the spatial consistency of our background model is an increased robustness against such small camera movements (see Figure
10↓).
Since samples are shared between neighboring pixel models, small displacements of the camera introduce very few erroneous foreground detections.
ViBe also has the capability of dealing with large displacements of the camera, at the price of a modification of the base algorithm. Since our model is purely pixel-based, we can make it able to handle moving cameras by allowing pixel models to follow the corresponding physical pixels according to the movements of the camera. The movements of the camera can be estimated either using embedded motion sensors or directly from the video stream using an algorithmic technique. This concept is illustrated in Figures
11↓ and
12↓.
The first series shows images taken from an old DARPA challenge. The camera pans the scene from left to right and the objective is to follow the car. Figure
12↑ shows a similar scenario acquired with a Pan-Tilt Zoom video-surveillance camera; the aim here is to track the person.
To produce the images of Figures
11↑ and
12↑, the displacement vector between two consecutive frames is estimated for a subset of background points located on a regularly spaced grid using Lucas and Kanade’s optical flow estimator
[106]. The global displacement vector of the camera is computed by averaging these pixel-wise displacement vectors. The pixel models are then relocated according to the displacement of the camera inside a larger mosaic reference image. The background model of pixels that correspond to areas seen for the first time is initialized instantaneously using the technique described in Section
3.2↑. It can be seen that, even with such a simple technique, the results displayed in Figures
11↑ and
12↑ are promising.
4.5 Resilience to noise
To demonstrate the resilience of ViBe to noise, we compared it to seven other techniques on a difficult noisy sequence (called “cable”). This sequence shows an oscillating electrical cable filmed at a large distance with a
40 × optical zoom. As can be seen in Figure
a↓, the difficult acquisition conditions result in a significant level of noise in the pixel values.
Background/foreground segmentation maps displayed in Figure
13↑ demonstrate that ViBe is the only technique that manages to combine a low rate of FP with both a precise and accurate detection of the foreground pixels.
Two factors must be credited for ViBe’s high resilience to noise. The first originates from our design, allowing the pixel models of ViBe to comprise
exclusively observed pixel values. The pixel models of ViBe adapt to noise automatically, as they are constructed from noisy pixel values. The second factor is the pure conservative update scheme used by ViBe (see Section
3.3↑). By relying on pixel values classified exclusively as background, the model update policy of ViBe prevents the inclusion of any outlier in the pixel models. As a result, these two factors ensure a continuous adaptation to the noise present in the video sequence while maintaining coherent pixel models.
4.6 Downscaled version and embedded implementation
Since ViBe has a low computational cost (see Figure
8↑) and relies exclusively on integer computations, it is particularly well suited to an embedded implementation. Furthermore, the computational cost of ViBe can be further reduced by using low values for
N and
♯min. Appendix
3↓ provides some implementation details and compares the complexity of ViBe with respect to the complexity of the first-order filter model.
In Figure
14↓, we give the PCC scores and framerates for a downscaled version of ViBe, which uses the absolute minimum of one comparison and one byte of memory per pixel. We also give the PCC scores and framerates for the full version of ViBe and for the two faster techniques from our tests in Section
4.2↑.
One can see, on the left hand side of the graph in Figure
14↑, that the downscaled version of ViBe maintains a high PCC. Note that its PCC is higher than that of the two GMM-based techniques tested in Section
4.2↑ (see Figure
a↑). In terms of processing speed or framerate, the zipfian
Σ − Δ filter method of
[8] is the only one to be faster than the downscaled version of ViBe. However, a post-processing step of the segmentation map is necessary to increase the low PCC score of the zipfian
Σ − Δ method, and the computational cost induced by this post-processing process reduces the framerate significantly.
To illustrate the low computational cost of ViBe and its simplicity, we embedded our algorithm in a digital camera. The porting work of ViBe on a
Canon PowerShot SD870 IS was performed with a modified version of the open source alternative firmware CHDK
. Parameters of ViBe were set to
N = 5 and
♯min = 1. Despite the camera’s low speed ARM processor, we managed to process 6 frames of
320 × 240 pixels wide images per second on average. The result is shown in Figure
15↓.
5 Conclusions
In this paper, we introduced a universal sample-based background subtraction algorithm, called ViBe, which combines three innovative techniques.
Firstly, we proposed a classification model that is based on a small number of correspondences between a candidate value and the corresponding background pixel model. Secondly, we explained how ViBe can be initialized with a single frame. This frees us from the need to wait for several seconds to initialize the background model, an advantage for image processing solutions embedded in digital cameras and for short sequences. Finally, we presented our last innovation: an original update mechanism. Instead of keeping samples in the pixel models for a fixed amount of time, we ignore the insertion time of a pixel in the model and select a value to be replaced randomly. This results in a smooth decaying lifespan for the pixel samples, and enables an appropriate behavior of the technique for wider ranges of background evolution rates while reducing the required number of samples needing to be stored for each pixel model. Furthermore, we also ensure the spatial consistency of the background model by allowing samples to diffuse between neighboring pixel models. We observe that the spatial process is responsible for a better resilience to camera motions, but that it also frees us from the need to post-process segmentation maps in order to obtain spatially coherent results. To be effective, the spatial propagation technique and update mechanism are combined with a strictly conservative update scheme: no foreground pixel value should ever be included in any background model.
After a description of our algorithm, we determined optimal values for all the parameters of the method. Using this set of parameter values, we then compared the classification scores and processing speeds of ViBe with those of seven other background subtraction algorithms on two sequences. ViBe is shown to outperform all of these algorithms while being faster than six of them. Finally, we discussed the performance of a downscaled version of ViBe, which can process more than 350 frames per second on our platform. This downscaled version was embedded in a digital camera to prove its suitability for low speed platforms. Interestingly, we found that a version of ViBe downscaled to the absolute minimum amount of resources for any background subtraction algorithm (i.e. one byte of memory and one comparison with a memorized value per pixel) performed better than the state-of-the-art algorithms in terms of the Percentage of Correct Classification criterion. ViBe might well be a new milestone for the large family of background subtraction algorithms.
Acknowledgments
We are grateful to Antoine Manzanera, who provided us with the code for his algorithms, and to Zoran Zivkovic for publishing his code on the Internet.
C-like source code for our algorithm
Pseudo-code of ViBe for grayscale images, comprising default values for all the parameters of the method, is given hereafter.
1int width; // width of the image
2int height; // height of the image
3byte image[width][height]; // current image
4byte segmentationMap[width][height]; // foreground detection map
5
6int nbSamples = 20; // number of samples per pixel
7int reqMatches = 2; // #_min
8int radius = 20; // R
9int subsamplingFactor = 16; // amount of random subsampling
10
11byte samples[width][height][nbSamples]; // background model
12
13for (int x = 0; x < width; x++){
14 for (int y = 0; y < height; y++){
15 // comparison with the model
16 int count = 0, index = 0, distance = 0;
17 while ((count < reqMatches) && (index < nbSamples)){
18 distance = getEuclideanDist(image[x][y], samples[x][y][index]);
19 if (distance < radius)
20 count++;
21 index++;
22 }
23 // pixel classification according to reqMatches
24 if (count >= reqMatches){ // the pixel belongs to the background
25 // stores the result in the segmentation map
26 setPixelBackground(segmentationMap[x][y]);
27 // gets a random number between 0 and subsamplingFactor-1
28 int randomNumber = getRandomNumber(0, subsamplingFactor-1);
29 // update of the current pixel model
30 if (randomNumber == 0){ // random subsampling
31 // other random values are ignored
32 randomNumber = getRandomNumber(0, nbSamples-1);
33 samples[x][y][randomNumber] = image[x][y];
34 }
35 // update of a neighboring pixel model
36 randomNumber = getRandomNumber(0, subsamplingFactor-1);
37 if (randomNumber == 0){ // random subsampling
38 // chooses a neighboring pixel randomly
39 (int neighborX, int neighborY) = chooseRandomNeighbor(x, y);
40 // chooses the value to be replaced randomly
41 randomNumber = getRandomNumber(0, nbSamples-1);
42 samples[neighborX][neighborY][randomNumber] = image[x][y];
43 }
44 }
45 else // the pixel belongs to the foreground
46 // stores the result in the segmentation map
47 setPixelForeground(segmentationMap[x][y]);
48 }
49}
Implementation details, and complexity analysis of ViBe and the first-order model
As computation times of hardware or software operations might depend on the processor or the compiler, it is hard to provide an exact analysis of the computation times. Instead, we present the steps involved for the computation of ViBe and the first-order filter model and evaluate the number of operations involved.
For ViBe, the evaluation runs as follows:
-
Segmentation step.
Remember that we compare a new pixel value to background samples to find two matches (♯min = 2). Once two matches have been found, we step over to the next pixel and ignore the remaining background samples. Operations involved during the segmentation step are:
-
comparison of the current pixel value with the values of the background model. Most of the time, the two first values of the background model of a pixel are close to the new pixel value. Therefore, we consider 2,5 (byte) comparisons on average per pixel (this is an experimentally estimated value).
-
1,5 (byte) comparisons of the counter to check if there are at least 2 matching values in the model; we only need to compare the counter value after the comparison between the current pixel value and the second value of the background model.
-
Update step:
-
1 pixel substitution per 16 background pixels (the update factor, φ, is equal to 16). Because we have to choose the value to substitute and access the appropriate memory block in the model, we perform an addition on memory addresses. Then we perform a similar operation, for a pixel in the neighborhood (first we locate which pixel in the neighborhood to select, then which value to substitute).
In total, we evaluate the cost of the update step as 3 additions on memory addresses per 16 background pixels.
-
Summary (average per pixel, assuming that most pixels belong to the background):
-
4 subtractions on bytes.
-
(3)/(16) addition on memory addresses.
For the first-order model, we have:
-
Segmentation step:
-
1 pixel comparison between an integer and a double number.
-
Update step:
-
2 multiplications and 1 addition on doubles, to perform Bt = αIt + (1 − α)Bt − 1.
-
Summary (per pixel):
-
2 multiplications and 2 additions on doubles
From this comparison, it appears that, once the random numbers are pre-calculated, the number of operations for ViBe is similar to that of the first-order filter model. However, if processors deal with “integer” (single byte) numbers faster than “double” numbers or if an addition is computed in less time than a multiplication, ViBe is faster than the first-order model.
References
[1] A. Cavallaro, T. Ebrahimi. Video object extraction based on adaptive background and statistical change detection. Visual Communications and Image Processing, 4310:465-475, 2001.
[2] A. Criminisi, P. Pérez, K. Toyama. Region filling and object removal by exemplar-based image inpainting. IEEE Transactions on Image Processing, 13(9):1200-1212, 2004.
[3] A. El Maadi, X. Maldague. Outdoor infrared video surveillance: A novel dynamic technique for the subtraction of a changing background of IR images. Infrared Physics & Technology, 49(3):261-265, 2007.
[4] A. Elgammal, D. Harwood, L. Davis. Non-parametric Model for Background Subtraction. Proceedings of the 6th European Conference on Computer Vision-Part II, 1843:751-767, 2000.
[5] A. Elgammal, R. Duraiswami, D. Harwood, L. Davis. Background and foreground modeling using nonparametric kernel density estimation for visual surveillance. Proceedings of the IEEE, 90(7):1151-1163, 2002.
[6] A. Manzanera, J. Richefeu. A new motion detection algorithm based on Σ-Δ background estimation. Pattern Recognition Letters, 28(3):320-328, 2007.
[7] A. Manzanera, J. Richefeu. A robust and computationally efficient motion detection algorithm based on Sigma-Delta background estimation. Indian Conference on Computer Vision, Graphics and Image Processing:46-51, 2004.
[8] A. Manzanera. Σ-Δ Background Subtraction and the Zipf Law. Progress in Pattern Recognition, Image Analysis and Applications, 4756:42-51, 2007.
[9] A. McIvor. Background subtraction techniques. Proc. of Image and Vision Computing, 2000.
[10] A. Mittal, N. Paragios. Motion-Based Background Subtraction Using Adaptive Kernel Density Estimation. IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), 2:302-309, 2004.
[11] A. Papoulis. Probability, random variables, and stochastic processes. McGraw-Hill, 1984.
[12] A. Srivastava, A. Lee, E. Simoncelli, S.-C. Zhu. On Advances in Statistical Modeling of Natural Images. Journal of Mathematical Imaging and Vision, 18(1):17-33, 2003.
[13] B. Lei, L. Xu. Real-time outdoor video surveillance with robust foreground extraction and object tracking via multi-state transition management. Pattern Recognition Letters, 27(15):1816-1825, 2006.
[14] B. Shoushtarian, H. Bez. A practical adaptive approach for dynamic background subtraction using an invariant colour model and object tracking. Pattern Recognition Letters, 26(1):5-26, 2005.
[15] B. White, M. Shah. Automatically Tuning Background Subtraction Parameters using Particle Swarm Optimization. IEEE International Conference on Multimedia and Expo:1826-1829, 2007.
[16] C. Jung. Efficient Background Subtraction and Shadow Removal for Monochromatic Video Sequences. IEEE Transactions on Multimedia, 11(3):571-577, 2009.
[17] C. Stauffer, E. Grimson. Adaptive background mixture models for real-time tracking. IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), 2:246-252, 1999.
[18] C. Stauffer, E. Grimson. Learning Patterns of Activity Using Real-Time Tracking. IEEE Transactions on Pattern Analysis and Machine Intelligence, 22(8):747-757, 2000.
[19] C. Wren, A. Azarbayejani, T. Darrell, A. Pentland. Pfinder: Real-Time Tracking of the Human Body. IEEE Transactions on Pattern Analysis and Machine Intelligence, 19(7):780-785, 1997.
[20] C.-C. Chiu, M.-Y. Ku, L.-W. Liang. A Robust Object Segmentation System Using a Probability-Based Background Extraction Algorithm. IEEE Transactions on Circuits and Systems for Video Technology, 20(4):518-528, 2010.
[21] D. Gutchess, M. Trajkovics, E. Cohen-Solal, D. Lyons, A. Jain. A background model initialization algorithm for video surveillance. International Conference on Computer Vision (ICCV), 1:733-740, 2001.
[22] D. Koller, J. Weber, J. Malik. Robust Multiple Car Tracking with Occlusion Reasoning. European Conference on Computer Vision (ECCV):189-196, 1994.
[23] D. Lee. Effective Gaussian Mixture Learning for Video Background Subtraction. IEEE Transactions on Pattern Analysis and Machine Intelligence, 27(5):827-832, 2005.
[24] D. Parks, S. Fels. Evaluation of Background Subtraction Algorithms with Post-Processing. IEEE International Conference on Advanced Video and Signal Based Surveillance:192-199, 2008.
[25] D.-M. Tsai, S.-C. Lai. Independent Component Analysis-Based Background Subtraction for Indoor Surveillance. IEEE Transactions on Image Processing, 18(1):158-167, 2009.
[26] E. Monari, C. Pasqual. Fusion of background estimation approaches for motion detection in non-static backgrounds. IEEE International Conference on Advanced Video and Signal Based Surveillance:347-352, 2007.
[27] H. Wang, D. Suter. A consensus-based method for tracking: Modelling background scenario and foreground appearance. Pattern Recognition, 40(3):1091-1105, 2007.
[28] H.-H. Lin, T.-L. Liu, J.-C. Chuang. Learning a Scene Background Model via Classification. IEEE Signal Processing Magazine, 57(5):1641-1654, 2009.
[29] I. Haritaoglu, D. Harwood, L. Davis. W4: Real-Time Surveillance of People and Their Activities. IEEE Transactions on Pattern Analysis and Machine Intelligence, 22(8):809-830, 2000.
[30] J. Cezar, C. Rosito, S. Musse. A Background Subtraction Model Adapted to Illumination Changes. IEEE International Conference on Image Processing (ICIP):1817-1820, 2006.
[31] J. Davis, V. Sharma. Background-Subtraction in Thermal Imagery Using Contour Saliency. International Journal of Computer Vision, 71(2):161-181, 2007.
[32] J. Davis, V. Sharma. Robust Background-Subtraction for Person Detection in Thermal Imagery. IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), 8:128, 2004.
[33] J. Jacques, C. Jung, S. Musse. Background Subtraction and Shadow Detection in Grayscale Video Sequences. Brazilian Symposium on Computer Graphics and Image Processing:189-196, 2005.
[34] J.-S. Hu, T.-M. Su. Robust background subtraction with shadow and highlight removal for indoor surveillance. EURASIP Journal on Applied Signal Processing, 2007(1):108-108, 2007.
[35] K. Kim, T. Chalidabhongse, D. Harwood, L. Davis. Background modeling and subtraction by codebook construction. IEEE International Conference on Image Processing (ICIP), 5:3061-3064, 2004.
[36] K. Kim, T. Chalidabhongse, D. Harwood, L. Davis. Real-time foreground-background segmentation using codebook model. Real-Time Imaging, 11(3):172-185, 2005. Special Issue on Video Object Processing.
[37] K. Toyama, J. Krumm, B. Brumitt, M. Meyers. Wallflower: Principles and Practice of Background Maintenance. International Conference on Computer Vision (ICCV):255-261, 1999.
[38] L. Lacassagne, A. Manzanera, A. Dupret. Motion Detection: Fast and robust algorithms for embedded systems. IEEE International Conference on Image Processing (ICIP):3265-3268, 2009.
[39] L. Lacassagne, A. Manzanera, J. Denoulet, A. Mérigot. High performance motion detection: some trends toward new embedded architectures for vision systems. Journal of Real-Time Image Processing, 4(2):127-146, 2009.
[40] L. Li, W. Huang, I. Gu, Q. Tian. Foreground object detection from videos containing complex background. ACM International Conference on Multimedia:2-10, 2003.
[41] L. Maddalena, A. Petrosino. A Self-Organizing Approach to Background Subtraction for Visual Surveillance Applications. IEEE Transactions on Image Processing, 17(7):1168-1177, 2008.
[42] M. Dikmen, T. Huang. Robust estimation of foreground in surveillance videos by sparse error estimation. IEEE International Conference on Pattern Recognition (ICPR):1-4, 2008.
[43] M. Seki, T. Wada, H. Fujiwara, K. Sumi. Background Subtraction based on Cooccurrence of Image Variations. IEEE International Conference on Computer Vision and Pattern Recognition (CVPR), 2:65-72, 2003.
[44] M. Sivabalakrishnan, D. Manjula. An Efficient Foreground Detection Algorithm for Visual Surveillance System. International Journal of Computer Science and Network Security, 9(5):221-227, 2009.
[45] M. Van Droogenbroeck, O. Barnich. Visual background extractor. 2009.
[46] M. Wu, X. Peng. Spatio-temporal context for codebook-based dynamic background subtraction. International Journal of Electronics and Communications, 64(8):739-747, 2010.
[47] N. Oliver, B. Rosario, A. Pentland. A Bayesian Computer Vision System for Modeling Human Interactions. IEEE Transactions on Pattern Analysis and Machine Intelligence, 22(8):831-843, 2000.
[48] O. Barnich, M. Van Droogenbroeck. ViBe: a powerful random technique to estimate the background in video sequences. Int. Conf. on Acoustics, Speech and Signal Processing (ICASSP):945-948, 2009.
[49] O. Barnich, S. Jodogne, M. Van Droogenbroeck. Robust analysis of silhouettes by morphological size distributions. Advances Concepts for Intelligent Vision Systems (ACIVS), 4179:734-745, 2006.
[50] P. KaewTraKulPong, R. Bowden. An improved adaptive background mixture model for real-time tracking with shadow detection. European Workshop on Advanced Video Based Surveillance Systems, 2001.
[51] P. Power, J. Schoonees. Understanding background mixture models for foreground segmentation. Proceedings of Image and Vision Computing:267-271, 2002.
[52] P. Varcheie, M. Sills-Lavoie, G.-A. Bilodeau. A Multiscale Region-Based Motion Detection and Background Subtraction Algorithm. Sensors, 10(2):1041-1061, 2010. URL http://www.mdpi.com/1424-8220/10/2/1041/.
[53] P.-M. Jodoin, M. Mignotte, J. Konrad. Statistical Background Subtraction Using Spatial Cues. IEEE Transactions on Circuits and Systems for Video Technology, 17(12):1758-1763, 2007.
[54] Q. Zang, R. Klette. Robust Background Subtraction and Maintenance. IEEE International Conference on Pattern Recognition (ICPR), 2:90-93, 2004.
[55] R. Abbott, L. Williams. Multiple target tracking with lazy background subtraction and connected components analysis. Machine Vision and Applications, 20(2):93-101, 2009.
[56] R. Cucchiara, C. Grana, M. Piccardi, A. Prati. Detecting moving objects, ghosts, and shadows in video streams. IEEE Transactions on Pattern Analysis and Machine Intelligence, 25(10):1337-1342, 2003.
[57] R. Radke, S. Andra, O. Al-Kofahi, B. Roysam. Image Change Detection Algorithms: A Systematic Survey. IEEE Transactions on Image Processing, 14(3):294-307, 2005.
[58] S. Cohen. Background estimation as a labeling problem. International Conference on Computer Vision (ICCV), 2:1034-1041, 2005.
[59] S. Elhabian, K. El-Sayed, S. Ahmed. Moving Object Detection in Spatial Domain using Background Removal Techniques — State-of-Art. Recent Patents on Computer Science, 1:32-54, 2008.
[60] T. Bouwmans, F. El Baf, B. Vachon. Statistical Background Modeling for Foreground Detection: A Survey. In Handbook of Pattern Recognition and Computer Vision (volume 4) . World Scientific Publishing, Jan 2010.
[61] V. Cevher, A. Sankaranarayanan, M. Duarte, D. Reddy, R. Baraniuk, R. Chellappa. Compressive Sensing for Background Subtraction. European Conference on Computer Vision, 5303:155-168, 2008.
[62] V. Mahadevan, N. Vasconcelos. Spatiotemporal Saliency in Dynamic Scenes. IEEE Transactions on Pattern Analysis and Machine Intelligence, 32(1):171-177, 2010.
[63] H. Wang, D. Suter. Background Subtraction Based on a Robust Consensus Method. IEEE International Conference on Pattern Recognition (ICPR):223-226, 2006.
[64] Y. Benezeth, P. Jodoin, B. Emile, H. Laurent, C. Rosenberger. Review and evaluation of commonly-implemented background subtraction algorithms. IEEE International Conference on Pattern Recognition (ICPR):1-4, 2008.
[65] Y. Sheikh, M. Shah. Bayesian Modeling of Dynamic Scenes for Object Detection. IEEE Transactions on Pattern Analysis and Machine Intelligence, 27(11):1778-1792, 2005.
[66] Y. Wang, K. Loe, J. Wu. A Dynamic Conditional Random Field Model for Foreground and Shadow Segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 28(2):279-289, 2006.
[67] Y. Wang, T. Tan, K. Loe, J. Wu. A probabilistic approach for foreground and shadow segmentation in monocular image sequences. Pattern Recognition, 38(11):1937-1946, 2005.
[68] Z. Zivkovic, F. van der Heijden. Efficient adaptive density estimation per image pixel for the task of background subtraction. Pattern Recognition Letters, 27(7):773-780, 2006.
[69] Z. Zivkovic. Improved adaptive Gaussian mixture model for background subtraction. IEEE International Conference on Pattern Recognition (ICPR), 2:28-31, 2004.